



the writer, who is the source of the errors occurring in the text
the end-user, who uses the system to edit the text
the reader, who the text is intended for
the customer, who is concerned with the overall quality of the system in relation to the requirements expressed by the writer, end-user and reader of a certain set-up, as well as with other considerations such as cost.
Each of these roles must be seen not as an individual with idiosyncratic properties and desires, but as a class. Note that some or all of these roles may be taken by the same person in a particular instance, or all may be taken by different persons.
The end-user's degree of competence in the language of the text, is important when looking at how good a system is at suggesting a correct replacement for a misspelled word. For an end-user with a good competence, being made aware of an error is more important than being provided with the right correction, especially if the end-user is also the writer of the text under consideration: a writer with a high level of competence in the language will typically make typing rather than spelling mistakes, and will find it easy to correct these errors once the system has spotted them[1]. For an end-user with poor spelling competence, on the other hand, being provided with the correct replacement
may be very important.
Functionality evaluation has constituted the focus of the project. The various functionality attributes are discussed in more detail further in this section.
The issue of how easy it is to install and use the same product across several platforms, on the other hand, is relevant in the context of adequacy evaluation. It has not, however, been treated any further in the project.
Usability is discussed in more detail further in this section.
For each attribute and sub-attribute, we have defined an appropriate measure, as well as a method to be used to get the measure for a concrete product. As mentioned above, depending on the characteristics of the participants in the various roles of a specific evaluation set-up, some sub-attributes may be more important than others. Thus, weightings can be attached in the PTB to specific sub-attributes: the final assessment will thus provide the customer with individual measures for each of the sub-attribute relevant to them, as well as with a weighted overall measure for each of the reportable attributes.
As mentioned above, the project has concentrated on a subset of the ISO quality characteristics, as not all of them seem relevant to adequacy evaluation, which is the main focus of the project, or especially distinctive in the context of either spelling or grammar checker evaluation.
Consequently, a serious attempt at breaking down quality characteristics into reportable attributes and sub-attributes, and to define methods and measures relevant to each of them, has only been done for functionality, usability and customisability.
They will be discussed in turn.
recall (the degree to which the checker accepts all the valid words of a language)
precision (the degree to which the checker rejects all the invalid words)
* suggestion adequacy (in case of invalid words, does the checker provide correct suggestions)
In this project, recall is defined as the degree to which a spelling checker accepts correct words of some language. That is, the checker is taken to be in essence a dictionary, and recall is seen as the completeness of this dictionary with respect to the vocabulary of the language (or, some specialized vocabulary; see below). To some, this way of using the term is confusing, as they tend to see a spelling checker as a thing that must react to errors, so that they would prefer to see recall as completeness with respect to the complement of the vocabulary; i.e., recall would mean the degree of rejection of non-words. Both views are equally sympathetic to us. In order to avoid confusion, we have decided to use only one throughout this report; rather arbitrarily, the first one has been chosen.
Recall is split into a number of more specific sub-attributes, as follows:
common word coverage
coverage of technical sublanguages
multi-word lexical items
closed sub-vocabularies (e.g., foreign loans, archaisms, slang, obscenities)
productive sub-vocabularies (e.g., numbers, units of measure, currency, dates, equations)
proper names
acronyms, initialisms, abbreviations, symbols
spelling variants
As can be seen, each of these sub-attributes is intended to account for the spelling checker's adequacy at recognising the vocabulary of a specific lexical domain.
Precision can be decomposed according to different error types, so that it can be investigated how well a system recognises specific error types. The taxonomy of errors the project has used includes the following categories:
typographical errors
spelling errors
medium-related errors (e.g. OCR errors)
Each of these can be further decomposed into more specific error types. In the case of mis-typings, these can be defined in terms of letter manipulations. In the case of misspellings, on the other hand, both the language of the writer and the kind of manipulation can be used as distinguishing features.
Typographical errors
Four basic typographical error types can thus be distinguished:
1. insertion
2. deletion
3. substitution
4. transposition
A spelling error defined by precisely one of these transformations is called a single-error item in Kukich (1992), who cites evidence showing that error items are most often single-error items, though the percentages vary.
The four types above can be broken down into a larger number of more specific error types, namely:
1. doubling: insertion of a letter X next to another X (bicycle > bicyccle) (special case of insertion)
2. singling: the opposite of doubling (winning > wining) (special case of deletion)
3. deletion of a randomly chosen letter (bicycle > bicyle)
4. interchanging of two letters (acknowledge > akcnowledge)
5. addition of a letter X next to a letter Y where X and Y are close on the keyboard (biocycle)
6. substitution of X by Y where X and Y are close on the keyboard (bicycle > bocycle)
All these error types have been treated by the project, in the sense that a methodology has been devised to generate instances of each error class for testing spelling checker adequacy. The list of error types may still be extended. Additional possibilities are:
* space insertion (bicycle > bic ycle)
* space deletion (blue bicycle > bluebicycle)
* space transposition (the girl > th egirl)
A taxonomy of spelling errors will be based on language-specific criteria, at least to some extent. A first distinction, as mentioned earlier, is that between misspellings made by native speakers and those made by foreign speakers. We have mainly concentrated on native-speaker misspellings. As an example, the following taxonomy of misspellings in Danish has been used as a basis to generate error instances:
* r-related errors
* errors of suffixation (not involving the letter r)
* silent letters (d, e, g, h, t, v)
* consonant doubling
* letter substitution (where the two letters are phonetically close)
* compounding errors
* errors in loan words
* syllable omission and syllable repetition
* other error types (apostrophe, capitalisation, etc.)
The typology has been set up on the basis of investigations of errors made by students in Danish primary and high schools (cf. Löb 1983 and Andersen et al. 1992) as well as relevant textbooks for native Danish speakers (Togeby 1989). Each type corresponds to a number of different errors (for more detail cf. Test Materials, TEMAA Deliverable 12) that can be expressed as a context-sensitive substitution of a character sequence with some other character sequence.
Most of today's spelling checkers do not just spot spelling errors but also suggest corrections for them. In this project, the attribute named `sugestion adequacy' is used for the evaluation of this part of the checkers functionality. Both of the checkers used as test cases perform this function.
In order to evaluate suggestion adequacy, one needs some general idea of what constitutes a `good' suggestion. In this project, we take the following view on this. A writer (including artificial writing devices like OCR) intends to write a given word W but, by mistake, writes W' (W' W). The difference between W and W' reflects some error type, as defined above. The text is then checked by some spelling checker C. If C concludes that W' is not correct, it offers a list of suggestions for changing W'. Clearly, the best suggestion would be to change W' to W. In fact, all other suggestions are equally useless. We therefore define W to be the unique correct suggestion. The way to operationalize this is to generate collections of W' from collections of W in systematic ways, reflecting types of mistakes that writers (in the general sense) tend to actually make.
In sum, suggestion adequacy is defined, in this project, in a context where each spelling mistake is derived from an intended word form, so that one can measure the degree to which suggestions lists offered by checkers contain the intended words.
invocation of spelling checker
selection of text for checking
error dialogue
text alteration
These tasks themselves decompose into a number of sub-tasks, some of which are optional or alternatives.
To evaluate the system's usability with respect to each of the basic tasks, we use a set of distinctions introduced in Jordan et al (1991): the differences between experienced user performance, guessability, and learnability. These dimensions, which are used instead of the distinction between novice and expert, in one sense flesh out the conventional wisdom that it should be easy to do simple things and possible to do difficult things; they add to this some consideration of how the system supports the development of the user's expertise.
Experienced User Performance (EUP)
For experienced users whose typing is in general fast and accurate, what we are evaluating here is in a sense the potential usability of the system, the performance level at which the learning curve levels off to approach an asymptote. This applies to all actual functions of the interface.
Guessability
It is not clear that user manuals are very relevant to spelling checkers, which rely heavily on guessability. Guessability is based largely on the similarity of a system's interface or operations to those of familiar packages. Thus a Macintosh user may be better able to guess how to use a new program that employs a dialogue format following the Macintosh user interface guidelines.
However, it turns out that having used any spreadsheet program, to take another example, is a basis for guessability, as it imparts some understanding of the kind of operations that must be offered in some way in a new instance of such a type, i.e., domain expertise makes a difference to what the user brings to guessability. Guessability may also be a function of the number of available options, so that, for instance, a system with a very rich set of functions will be less guessable (and may have lower EUP) than a simpler one that happens to fit the experienced user's needs and also is guessable.
Learnability
Learnability describes the nature of the learning curve by which novice users can approach the asymptotic performance of EUP. One criticism levelled at `intuitive' interfaces, for example, is that it is hard to get beyond what is intuitive; the user never has occasion to learn that there may be faster and better ways to do tasks. The usability of on-line help or printed manuals is one factor in this, as is the number of options available (with too many options the user may find it harder to learn an optimum selection for his or her own tasks).
Our consideration of the dimensions of usability suggests that we can think of three questions to ask about each task or subtask:
"What can you do?" (task set)
That is, what operations or commands are available to accomplish this task?
"How easy is it to use for an experienced user?" (EUP)
"How easy is it to learn for a novice user?" (guessability, learnability)
Creating and using dictionaries
defining user dictionaries;
loading user dictionaries;
defining error dictionaries.
Maintaining dictionaries
inspecting user dictionaries;
adding words;
deleting words.
Sharing dictionaries
sharing user dictionaries among different users;
merging dictionaries.
For each of the sub-tasks given above, we have a sub-attribute for the basic facts about what is possible, in terms of whether and how a task is supported, for example what number of dictionaries can be accessed simultaneously during spelling checking.
There appears to be an important distinction between what can be done from within the checking program and what cannot. We define a sub-attribute with related measure for some subtasks in terms of whether a particular function is available from within the checking program or outside it; we feel that both options could be desirable in order to allow the user to create a customised dictionary during the checking process, but also to be able to predefine a dictionary, before the checker is ever run.
Additionally, we feel that information indicating how easy it is to create, modify and update user dictionaries would be useful to the user. Clearly notions of ease of use can depend on particular users' usual modes of working; however, we feel that the measures we have chosen (see Section 3.1.3.5) can be reported on and will enable the customer to form their own idea of how easy it is to customise the checker.
* How many of the words in the list are recognised by the spelling checkers?
This is a numeric measure, whose value is a percentage between 0 and 100
The simplest way to express this measure is by giving the percentage of words recognised out of the total number of words in the list. There will also be cases, however, where coverage of some sub-attribute will be expressed as a weighted percentage. To test common word coverage, for example, we propose to use a structured list of words, i.e., a list consisting of a number of separate sublists, defined on the basis of frequency of occurrence. For each sublist, then, we count the percentage of recognised words. In order to obtain a single coverage value for the whole list, the single percentages will be weighted to reflect the relative frequency of the words contained in each sublist. A weighted mean score will then be calculated and presented to the customer as the total value for common word coverage in addition to the simple percentages obtained for each sublist.
Thus, we use weights to relate coverage values to the different frequencies of different groups of words belonging to the same domain. It may be objected that the use of weights makes the results difficult for the customer to interpret. However, we believe that different users will be interested in different portions of the lexicon, and that it is important, therefore, to provide rather differentiated coverage values. For instance, technical writers may not want to evaluate a spelling checker on the basis of its total coverage of the general vocabulary of a certain language. However, the most frequent common words of that language will also be relevant to them. Thus, the only common word coverage value which is of interest to them is the percentage obtained on the group of most frequent words. Writers of fiction, instead, will use a much larger general vocabulary. However, coverage of the most frequent common words will still be more important than coverage of rarer words, and must therefore receive more weight in the calculation of the overall score.
Unless a spelling checker has perfect recall, there will be correct words that it nevertheless rejects. These are called false positives in this report. Expressing recall as a percentage R, it is clear that the percentage F of false positives is computed by F = 100 - R.
For example, a whole range of existing checkers detect no errors at all in the following sentence, because they cannot treat multi-word units:
"A man ad his woman tend to hoc together."
This behaviour enables these checkers to accept the idiom ad hoc (thereby improving their scores on the recall attribute) but it is questionable whether this improves the checkers' behaviour as a whole.
Our approach to measuring precision is in essence the same as that proposed for recall. As discussed in Section 3.1.2.1.2, we define a set of error types. For each error type, we apply a spelling checker to a collection of non-words containing errors of this type, and we determine how many of them are rejected.
This is a numeric measure whose value is a percentage beween 0 and 100
In the example case, clicking on Change will cause the checker to replace speling with spelling. If the user clicks on one of the other suggested corrections first, that one will be the replacement.
A suggested correction makes sense only if it actually is the intended word. In the example, the first suggestion is the right one if the user actually intended to type spelling.
The term suggestion adequacy denotes the degree to which a spelling checker produces suggestions that can actually be used as replacements for spelling errors.
In order to set up a measure for evaluation of the usefulness of suggestions like the examples above, we will distinguish:
source item
error item
suggestion
An error item is an item which is not included in the valid words of the language under consideration. A source item is the item that the user intends to be in the text instead of the error item. A suggestion is an item suggested by the checker as a correction for the error item.
As suggestions are listed in some order, we will refer to the Nth suggestion for some integer N.
We will say that a suggestion for some error item E is a hit if it is identical to the source of E; we will say that it is a miss otherwise.
Evaluation measures for the adequacy of suggestions should reflect how often one of the suggestions is a hit. Moreover, we want to know if the first suggestion is a hit, as this is the best possible result. The worst result, on the other hand, is provided if there is no hit visible on the spelling checker window, or if all the visible suggestions are wrong. In other words, we don't consider the possibility of additional replacements which the user can only have access to by extending the window: even if they may be correct, they are too difficult to get to.
We therefore decompose suggestion adequacy into four sub-attributes which will be our suggestion adequacy measures:
How often is the first suggestion a hit?
How often is a visible suggestion a hit?
How often are all visible suggestions wrong?
How often are no suggestions presented at all?
Each of these is a numeric measure whose values is a percentage between 0 and 100.
Invocation of spelling checker
How is the spelling check initiated? For the most part, this boils down to the question of whether the speller runs as a command in another program such as a word processor or as a standalone program.
Means of initiation. This is a factual measure, taking values that are a subset of {standalone, word processor command}.
How easy is it to invoke the spelling checker (from each of the available methods)? This is an operation count measure.
Selection of text for checking
The second stage is the selection of text for checking.
What unit of text can be selected for spell-checking? This measure is a subset of {one word, selection, whole text}.
How easy is it to do in each case that is offered? This is an operation count measure.
Error dialogue
A significant class of users require the correct suggestion to be the first on the list, partly, seemingly, because any accelerated commands such as one-click replacement apply only to the first suggestion, and hence accepting lower suggestions involves considerably more user operations.
For example, Microsoft Word 3 requires a separate user operation to show suggested replacements, which, although it may speed up the initial dialogue, puts an extra burden on users who want to see suggestions.
The measurements we make here may be a little more complicated since the dialogue with the user may involve a number of user choices, not all of which will be present in every case. The choices can be tentatively listed as follows:
dismiss error suggestions and make no replacement;
dismiss suggestions and save word to a user dictionary (this is covered under customisability);
accept first suggested replacement;
accept second or lower suggestion replacement;
submit a replacement not on the list of suggestions.
Each of these actions (which are of course sub-tasks) can be analysed for the ease with which they can be carried out. Note that the relative importance of each will vary with the performance of the checker on its coverage and replacement suggestion attributes: if, for whatever combinations of writer, text type, and checker, the level of false positives is high, it is particularly important that the first and second options should be easy; if the suggestions are in general poorly ordered, it is more important that second and lower suggestions be as easy to select as the first. However, on average we are likely to want to give more importance to the measurement for accepting the first suggestion and dismissing the suggestions, each of which should have the most direct possible commands. The error dialogue, then, has one usability measure for each user action:
How easy is it to execute the action? This is an operation count measure.
Text alteration
There may still be spelling checkers that make it difficult to actually convert the user's decision in an error dialogue to changes in the text; certainly this is necessarily true of much of the operation of grammar and style checkers. Under this heading we also consider the possible desirability of retaining a record of changes suggested and made; this may not be typically required for a `general purpose' spelling checker, but for various types of user, such as those involved in group authoring, this could be a valuable function.
What types of text alteration facility are available? This measure is a subset of {automatic text replacement, user alteration}
What kinds of recording of text alterations is possible? This measure is a subset of {none, record changes, record proposals}
Guessability
Our measure for guessability is applied to each coherent task set as a whole. Thus, we have only one such measure for the basic checking task, and another for customisability. We propose one overall measure to be a rating scale with values from 1 to 5, plus a measure to be expressed in a short structured prose report detailing task/command mappings (i.e., the number of key strokes or mouse operations) that are found problematic to various kinds of users.
Learnability
Learnability means how easy it is to find out how to use the checker. Thus, we want to evaluate any learning resources by use of which a user's expertise can increase.
What learning resources are available? This measure is a subset of {on-line help, printed manuals}.
For each learning resource, we have evaluative measures:
* Learning resource completeness. We propose to measure learning resource completeness by using the task/command mapping, giving a rating scale score from 1 to 5 based on the proportion of tasks that are adequately represented in the manual.
* Learning resource quality. Quality and clarity of user manuals or indeed on-line help might be more difficult to measure. Whilst there are standard indices of so-called clarity of writing, they are somewhat controversial, and it is difficult to see that they would produce any reliable results on what are likely to be very small pieces of text. We provisionally give a measure that is a simple rating scale, 1-5, plus perhaps a short structured prose report based around tasks or commands that are particularly hard to learn.
* Completeness of indices. This measure is a rating scale 1-5, or no-index.
Defining user dictionaries
* How many user dictionaries can be defined? Factual numeric measure.
* In what ways can a user dictionary be defined? This measure is a subset of {inside checker, outside checker, non-applicable (N/A)}.
* How easy is it to create a new dictionary from inside the checker? This measure is operation count or N/A.
Loading user dictionaries
* How many user dictionaries can be loaded for simultaneous access? Factual numeric measure.
Defining error dictionaries
Defining error dictionaries may need some explanation. It amounts to defining a dictionary of valid words which are closely related to another valid word but which would nevertheless be inappropriate to the domain to which a particular document belongs. For example in Italian, one may want to exclude the word coniglio (rabbit) so that the spelling checker interprets that string as a misspelling of the word consiglio (committee). In other words, is it possible to block the acceptance by the checker of otherwise valid words when checking a particular text?
* Is it possible to define error dictionaries? The values for this measure would be either positive or negative (yes/no).
Inspecting user dictionaries
* How can user dictionaries be inspected? This measure is a subset of {inside checker, outside checker} or `not offered'.
Adding words to user dictionaries
* How can a new word be added? This measure is a subset of {inside checker, outside checker}.
* How easy is it to add a new word from inside the checker? This measure is operation count.
Deleting words from user dictionaries
* How can a word be deleted? This measure is a subset of {inside checker, outside checker}.
* How easy is it to delete a word from inside the checker? This measure is operation count.
Sharing user dictionaries
Finally, we would also add an attribute regarding the number of users who can access a single user-defined dictionary at one time. Again this is subdivided into two questions: what is possible within the spelling checking program? And what is possible outside it?
* Can more than one user simultaneously modify a single user-defined dictionary from within the spelling checker program? This measure is (yes/no).
* How easy is it to do this? This measure is operation count or N/A.
* Is it possible to merge different user-defined dictionaries into one, outside the spelling checker program? This measure is (yes/no).
Establishing values for the attributes that are not decomposed (the leaves of the attributes tree) involves performing tests on objects of evaluation. In this section, we describe testing methods for the attributes defined above.
An important part of the TEMAA philosophy has been that tests for evaluation should be automated wherever possible. This would serve the repeatability of tests in the very first place, but it would also be in the interest of testing efficiency.
The Parametrisable Test Bed (chapter 4) contains some programs that support testing: Errgen supports the construction of lists of mis-spelled words, and ASCC runs spelling checkers on test data to produce statistics on recall, precision and suggestion adequacy.
But it should be clear from the start that, for several quality characteristics, no automatic methods are possible. For example, testing characteristics like guessablity and learnability essentially involves human action. Also, the construction of basic lists of correct words can not be done by computers.
In this section, we describe the construction of data used in testing recall, precision, and suggestion adequacy of spelling checkers, and, more informally, methods for testing usability and customisability.
We distinguish two kinds of word lists: lists of valid words, which we call base lists, and lists of corrupted ones, which we call error lists. Base lists are used to test a spelling checker's recall (for different lexical coverage sub-attributes), to construct error lists, and to test suggestion adequacy. Error lists are used to test the checker's precision and suggestion adequacy.
Different methods can be envisaged to construct base lists, e.g., using frequency word lists, lemmatised lists taken from existing published dictionaries, manually-constructed or automatically-constructed samples.
TEMAA has opted for frequency word lists where possible, i.e. where such lists were available or where it was possible to construct them within the project. We were interested in lists of inflected words, as words in running text occur as inflected full forms, and not all forms of the same lexeme are equally frequent. Furthermore, we wanted to be able to distinguish between different degrees of frequency when testing the lexical coverage of the various domains. In fact, it is very important for a spelling checker to be able to recognise the most used words of the domain correctly in order not to bother the user with too many false flaggings. On the other hand, it may also be of particular interest to know how well a spelling checker performs at correcting misspellings of infrequent words, which are the ones a user is most likely to misspell.
The validity of the test results obtained with a frequency word list as input, however, depends on the quality of the list, i.e. on its representativeness and correctness. The issue of correctness is particularly relevant because of the purpose the list is intended to serve. Thus, base lists must have been proofread to remove systematic typos and spelling errors. Sporadic errors, of course, are difficult to eradicate, but precisely because of their sporadic nature they will only appear among the most infrequent words. Examples of systematic and apparently conscious deviance from the spelling norm on the part of an author, instead, should be kept in the list as possible variants. Representativeness of the input list, on the other hand, is necessary to ensure that the results reflect coverage of the intended domain, and not something else. The representativeness of a frequency word list depends on the way in which the corpus it is built from has been defined and assembled. Criteria to be met are variation on the one hand, and homogeneity on the other. The former is needed to avoid the systematic influence of individual texts or themes on the overall lexical material. The latter ensures that the characteristics of the corpus can be generalised to texts of the same type and domain.
In TEMAA, frequency word lists are used for example to test a system's coverage of the standard vocabulary of the language. For Danish, such lists have been identified in Maegaard & Ruus (1986). This is a collection of the lists derived from five different corpora representative of different text types, namely fiction for adults, children's fiction, newspapers, magazines and professional publications. Together, the five corpora represent the most frequent standard vocabulary of modern Danish. The corpora used to derive the word lists are made up of randomly chosen text samples of 250 words each, to ensure reasonable variation. The decision to have five separate corpora for distinct text types rather than a unified corpus of texts in modern Danish is motivated by the homogeneity criterion. In fact, the most frequent content words are different in the different lists. Additionally, still to ensure homogeneity, publications were selected from a relatively short period, namely 1970-1974. More details on the principles used to built the corpora are given in Maegaard & Ruus (1987).
One of lists in the collection has been used for actual testing, namely the list covering the domain of general interest magazines[2]. The size is approximately 6,800 words, covering around 82% of the corpus. The list was divided into three frequency classes, as shown in the following table (figures have been rounded up):
|
class interval
(number of words)
|
relative
frequency
of each class (%)
|
relative
cumulative
frequency (%)
|
| 1-189
|
48
|
48
|
| 190-1732
|
21
|
69
|
| 1733-6780
|
13
|
82
|
The results of testing are provided in two different ways, either as simple percentage scores showing the proportion of words recognised by the checker for each class, or as a weighted mean score showing the overall performance for the list as a whole. The weights used correspond to the relative frequencies of the various classes.
For Italian, ISSCO has constructed a frequency word list on the basis of ANSA news wire bulletins, dated from January 1995 to end of April 1995. The corpus was filtered to obtain accented characters in the ISO 8859_1 character set; in order to avoid noise in the frequency with proper names, acronyms and so on, capitalized or uppercase words were deleted. The list consists of 16,530 words; low frequency words account for about 50%. This list can be considered representative of current newspaper style and language. As it was derived from published material, the amount of errors or mis-typings is probably minimal, and in the lowest frequency category. Because any manual correction might have inserted other undesirable errors, we automatically sorted capitalised words and figures, and deleted them from the list.
Moreover, ISSCO was given a larger frequency list from Istituto di Linguistica Computazionale in Pisa, consisting of 244,191 words. Since this list is composed from much broader material, we restricted the word list used for testing to words that had a relatively high frequency (over 20 instances found in the corpus), thus limiting the list to 33,377 words in total.
Also for technical sublanguages, we believe the frequency word list approach would be a fruitful one. So, for each technical domain of interest to the user, a separate word list should be used to test the spelling checker's lexical coverage.
In a particular case, namely words belonging to the closed part of speech classes, exhaustive word lists can be constructed. We have provided an example of such a list for Danish: this is a list of determiners, pronouns, prepositions, conjunctions and non-productive adverbs. The list was constructed automatically by extracting the relevant word forms from the electronic version of the Danish spelling dictionary (Retskrivningsordbogen 1986).
For other sub-attributes of lexical coverage, including multi-word units, closed sub-vocabularies (e.g., foreign loans, archaisms, slang, obscenities), proper names, acronyms, initialisms, abbreviations, and symbols, the project had foreseen using limited samples, constructed manually or semi-manually. We have actually constructed three different lists to treat coverage of loan words and of proper names.
For Danish, we have a list of loan words from the technical domain of computer science, in which a large number of English terms are used. This is a manually constructed distributed sample of 95 words extracted from a printed dictionary of computer terms (Politikens Dataleksikon 1986). The dictionary includes both Danish and English words. To build this list, we made use of a method described in D2 (Survey of Existing Practices Within the Consortium: Spelling Checkers). To obtain a sample of 100 terms[3] from a dictionary of approximately 500 pages, we took the first English term on every fifth page. Since we could not always find an English term on the page chosen, we had to repeat the procedure by taking a term from every 17th page, and again from every 20th page. In the end, we had a sample of 100 terms, which we ran through a spelling checker to remove spelling errors. For five of the terms chosen, the spelling checker suggested an alternative spelling. To make sure that we did not introduce unconventional spellings in the sample, we removed those five forms.
For Italian, two lists of proper names have been constructed, one containing the names of all Italian capitals of provinces (capoluoghi di provincia) for a total of 99 cities, and the other containing first names, for a total of 593 names. From this another list was also derived, containing the adjectives referring to the inhabitants of those cities.
The English base lists are (i) a list of 288 closed class words drawn from the Alvey Grammar 3rd release (lexicon file d.le), (ii) a list of 9532 general open class words derived from the British National Corpus ([BNC]) via word/part of speech frequency lists compiled by Adam Kilgarriff of the University of Brighton, kindly made available by anonymous ftp [AK], and (iii) a list of 32,250 technical words drawn from the European Corpus Initiative CDROM (ECI).
The project had also foreseen the use of domain-related grammars to generate samples relative to other sub-attributes of recall, e.g. numbers, units of measure, and dates. An example of such test suites has been provided for Italian in the form of a list of adjectives referring to people's age and of ordinal numbers in full letters.
In conclusion, the collection of word lists provided ranges over a broad selection of recall sub-attributes and constitutes, in our opinion, a good exemplification of the methods set up by the project.
Common practice in most spelling checker evaluations (cf. Green & Hendry 1993) is to use limited samples of particularly tricky words, i.e. words which the evaluator supposes will be hard for the checker to spot for different reasons. Automation of the error generation process and of spelling checker testing, on the other hand, makes it possible to check spelling checker behaviour against large error samples. This has been done in TEMAA by designing language-specific corruption rules and applying them to some of the word lists used to test lexical coverage.
The project has concentrated on mis-typings and misspellings. In particular, for Italian we have tested how well spelling checkers recognised and corrected two kinds of mis-typings (consonant doubling and undoubling). In addition, different types of misspellings were tested for both Italian and Danish. The thrust of our work has been to formalise the description of spelling errors so that they could be treated automatically: automation, in fact, allows us to work systematically with large samples of data - a necessary precondition to offer reliable figures on the performance of different checkers. With automation as a general goal, two factors are crucial to determine whether a misspelling can be treated by our evaluation method:
* whether the error can be generated automatically by some mechanical and systematic substitution, deletion or addition of letters
* whether the invalid form is invalid in all contexts.
For instance, among the misspelling categories identified by Löb (1983) for Danish are idiosyncratic errors for which no systematic mapping between the valid and the invalid forms seems possible (e.g. *indtasitter for intercitytog, En: intercity train). Such errors cannot be generated automatically and therefore fall outside the scope of our evaluation package. In fact, they are also very difficult for any spelling checker to handle intelligently.
The second group of misspelled words that constitute a problem in our case are the so-called `false negatives' . A false negative is a misspelled word which is wrong in the current context, but may be correct in others. The correct and the `incorrect' words are often homophones, i.e. they have the same pronunciation but different orthographies (e.g. in Danish at *terroriserer for at terrorisere, English: to terrorise). These errors are systematic, and can easily be generated automatically. However, since spelling checkers check words one at a time without taking the context into account, false negatives cannot be detected. Therefore, they are not treated in the evaluation package.
Practical considerations played a role in determining the approach to suggestion adequacy taken in the project. Suggestion adequacy is tested by checking whether one of the suggestions offered by the checker matches the original valid word, and by taking the position of the correct suggestion in the suggestion window into account. However, the checker may sometimes provide a suggestion which does not match the original input, but is nevertheless a plausible replacement for the error in question. Taking this into account would make automation of the testing considerably more complex.
Another issue concerns the accuracy of our corruption rules. It is not always possible to state the transformation needed to generate a certain error with enough precision, and undesired transformations are sometimes carried out. Two types of "false" errors may in fact be produced: on the one hand words that are not actually misspelled at all (i.e. corruption rules unintentionally generate a different valid word), on the other, words that do contain an error, but not a very plausible one. The first type of false error is not too problematic. The Errgen program (cf. section 4.4.5) checks all the generated items against a base list to make sure that they are not valid words of the language. Provided that the base list is large enough, valid words will thus be recognised.
The other kind of unwanted output, on the other hand, seems more difficult to get rid of completely due to the fact that for a particular language, it may not always be possible to narrowly restrict the context in which the error should be inserted. For example, a possible misspelling in Danish can originate as a result of confusion between the two participial endings t and et, which are used in connection with verbs belonging to two different classes. An example would be De har *slæbet (English: They have dragged), where the participial form should read slæbt. Assuming that the relevant corruption rule would simply substitute et for t as an ending, one would also generate less plausible misspellings, e.g. with an adjective:
hårdt (English: hard) > *hårdet
The problem here is that the grammatical category of the input word is not checked to constrain the application domain of the rule. To avoid the generation of such unlikely errors, therefore, a certain amount of manual checking seems unavoidable.
Nevertheless, we feel that the approach to error treatment taken in TEMAA is fundamentally a sound one, and the test results obtained (cf. An Experimental Application of the TEMAA Evaluation Framework: Spelling Checkers, TEMAA Deliverable 13), show that the metrics set up for error treatment are able to elicit useful information about different spelling checkers' degree of precision with respect to different error types.
Finally, an important aspect that has not been treated by the project is how the various error types relate to different user types. If frequency information relative to the various error types were available, it would increase the significance of the results obtained.
* Semi-structured interviews
The user survey carried out in the initial phase of the project represented the first level of an empirical user-based investigation using a telephone questionnaire that operated like a semi-structured interview, although the usability aspects discussed were necessarily very general.
The main weakness of this as a method for eliciting usability evaluations stems from the remoteness from actual use, compared with behavioural observations. Many of the design problems of interfaces are not specifically recalled in such an interview. Strong points of interviews are general attitude evaluations, and, of course, the saving of user and investigator time.
* Think-aloud protocols
In a think-aloud method, actual users are observed in the course of a (relatively) realistic task. As the requirements of the task cause them to use or seek to use the various commands of the system, they are encouraged to keep up a commentary on their reactions: their goals, their attempts to find ways of satisfying them, the difficulties they encounter. Such sessions may be recorded on video or audio tape for ease of processing if the information required from the think-aloud is not easy to extract. The great advantage of this is the real insight into usability difficulties that it produces; this makes it particularly suitable to measure learnability problems, for instance. The disadvantages include the difficulty in deciding whether problems encountered are representative without huge duplication, the expensive and time-consuming nature of working with users, and the difficulty of converting the record of such a protocol to a concise measure.
A think-aloud should be guided by a list of questions we want an answer for, probably focused around the commands and measures: i.e., for each command, how easy it is to learn. The task the user is asked to do is defined accordingly, and the researcher's note-taking focused on those questions. A marking scheme should be established, whereby a given level of user response is judged to fall into categories of difficulty or ease.
* Researcher tests
A researcher test may be similar to a think-aloud, except for the greater convenience of not having to find users. Where we can be sure that an attribute can be representatively measured by a researcher's own experience, this is clearly the method of choice.
* Operation counting with the command/task mapping
When we are evaluating the ease of use of a given command, it will often be realistic to measure its experienced user potential simply in terms of the number of keystrokes or mouse commands required to effect the command, which we called an operation count measure. The actual method of obtaining this measure is taken to involve the creation of a task/command mapping, which relates the general tasks and subtasks we identify with a sequence of commands in each particular system.
Given the operations in the basic spelling task described in Section 3.1.3.4, a method can be established for each of them out of the method types given above. Additionally, usability evaluation involves methods for general guessability and learnability evaluation across the four basic task operations. All the concrete methods suggested by the project are listed in the following subsections.
Invocation of spelling checker
* Means of initiation. This is a factual measure, taking values that are a subset of {standalone, word processor command}.
Method: researcher test to corroborate literature statement of means available.
* How easy is it to invoke the spelling checker (from each of the available methods)? This is an operation count measure.
Method: researcher test of operation count using instructions available in the literature expressed in the task-command mapping.
Selection of text for checking
The second stage is the selection of text for checking.
* What unit of text can be selected for spell-checking? This measure takes a factual value, from the set {one word, selection, whole text}.
Method: From inspection of user literature, corroborated by researcher test.
* How easy is it to do in each case? This is an operation count measure.
Method: researcher test of operation count using instructions available in the literature expressed in the task-command mapping.
Error dialogue
The following sub-tasks are considered to be part of the error dialogue:
* dismiss error suggestions and make no replacement;
* dismiss suggestions and save word to a user dictionary (this is covered under customisability);
* accept first suggested replacement;
* accept second or lower suggestion replacement;
* submit a replacement not on the list of suggestions.
For each,
* How easy is it to execute the action? This measure is operation count.
Method: researcher test of operation count using instructions available in the literature expressed in the task-command mapping.
Text alteration
* What types of text alteration facility are available? This measure is a subset of {automatic text replacement, user alteration}.
Method: researcher test using task-command mapping.
* What kinds of recording of text alterations is possible? This measure is a subset of {none, record changes, record proposals}.
Method: researcher test of operation count using instructions available in the literature expressed in the task-command mapping.
Guessability
Values for both the guessability measures we are interested in derive from the same test, with somewhat different reporting. The test would be a think-aloud protocol on a number of users drawn from those who are familiar with spelling checkers, those who are familiar with the platform conventions, and those who are not. They would be set a task of checking a text with various errors and false positives that exercises all the task sets identified so far. The researcher would use the task/command mapping as a skeleton to note where tasks take a long time, prompt extensive experimentation, or result in errors. Each task would be given ratings based on the number of problems experienced by all the subjects. Differences between user types would be noted.
* Guessability index: We propose one overall measure to be a rating scale with values from 1 to 5.
Method: For the first measure, a sum will be obtained of all the problem scores obtained from the think-aloud report, and a value calculated such that high problem scores map to low guessability, low problem scores to high guessability. Note that this will require preliminary calibration with a reasonable number of test cases to establish suitable mappings.
* Guessability report: Measure to be expressed in a short structured prose report detailing task/command mappings that are found problematic to various kinds of users.
Method: For the second measure, tasks causing problems above a given threshold overall will be noted, and any tasks that cause problems that are differently distributed among the user types will be noted.
Learnability
* What learning resources are available? This measure is a subset of {on-line help; printed manuals}.
Method: researcher test based on product inspection.
The test to be used here is a think-aloud experiment, possibly as an extension to the one described above, in which the user is asked to comment on their reaction to using the available learning resources including their indexes. For each learning resource, we have methods for the following evaluative measures:
* Learning resource completeness. Measure: rating scale score from 1 to 5.
Method: We propose to measure learning resource completeness by using the task/command mapping, giving a rating scale score from 1 to 5 based on the proportion of tasks that are adequately represented in the manual. Judging adequate representation is likely to be rather a subjective component of this method.
* Learning resource quality. Measure: a simple rating scale, 1-5, plus a short structured prose report based around tasks or commands that are particularly hard to learn.
Method: Using the same think-aloud, but with more emphasis on the quality rather than the presence or absence of entries for tasks and commands. Similar scoring and summing of responses for the rating scale. For the structured report, the choice of tasks with above-threshold problems or user-group specific problems is similar to the guessability methods in the previous section.
* Completeness of indexes: This measure is a rating scale 1-5, or no-index.
Method: Using the same think-aloud, the problem here is to find a list of terms under which the various tasks and commands ought to be indexed to make it easy enough. A possible way of doing this is by a structured interview in various types of users are asked how they would want to describe the tasks they are set.
* How many user dictionaries can be defined? Factual numeric measure.
* In what ways can a user dictionary be defined? This measure is a subset of {inside checker, outside checker, N/A}.
* How easy is it to create a new dictionary from inside the checker? This measure is operation count or N/A.
Method: researcher test using task/command mapping on the basis of manuals and testing.
Loading user dictionaries
* How many user dictionaries can be loaded for simultaneous access? Factual numeric measure.
Method: researcher test using task/command mapping on the basis of manuals and testing.
Defining error dictionaries
* Is it possible to define error dictionaries? The values for this measure would be either positive or negative (yes/no).
Method: researcher test using task/command mapping on the basis of manuals and testing, although it is not clear how such a facility may be described in a user manual. It may be that such a masking facility is not available in terms of defining a separate dictionary, but rather by flagging items in already existing dictionaries.
Inspecting user dictionaries
* How can user dictionaries be inspected? This measure is a subset of {inside checker, outside checker} or `not offered'.
Method: researcher test using task/command mapping on the basis of manuals and testing.
Adding words to user dictionaries
* How can a new word be added? This measure is a subset of {inside checker, outside checker}.
* How easy is it to add a word from inside the checker? This measure is operation count.
Method: researcher test using task/command mapping on the basis of manuals and testing.
Deleting words from user dictionaries
* How can a word be deleted? This measure is a subset of {inside checker, outside checker}.
* How easy is it to delete a word from inside the checker? This measure is operation count.
Method: researcher test using task/command mapping on the basis of manuals and testing.
Sharing user dictionaries
* Can more than one user simultaneously modify a single user-defined dictionary from within the spelling checker program? This measure is (yes/no).
* How easy is it to do this? This measure is operation count or N/A.
* Is it possible to merge different user-defined dictionaries into one, outside the spelling checker program? This measure is (yes/no).
Method: researcher test using task/command mapping on the basis of manuals and testing.
Problem checking
The basic functionality of the grammar checker, as of the spelling checker, is to find errors in a text produced by a given type of writer and respond in such a way as to allow the end-user to correct the errors so that the text is suitable for a given type of reader.
Correction support
It may be of more relevance for grammar checkers than for spelling checkers to separately consider the issue of supplementary material to support the activity of verifying an error diagnosis and composing or selecting a replacement. Partly this is because there can be no simple look-up list of grammatically correct instances, corresponding to the dictionary for spelling checkers, hence more vaguely defined and pedagogically oriented reference materials are likely to be required. It is hard to imagine how to go about evaluating such material from a Linguistic Engineering perspective; the expertise required is firmly of an educational variety.
A more traditional idea of reliability in terms of the likelihood of a system crashing in the course of its duties (which is somewhat implied by the ISO definition in terms of "for a stated period of time") might be seen as more relevant to grammar checkers than spelling checkers. Being more complicated technology and more demanding in terms of computational resources, there is rather more to go wrong with such software systems, and indeed those currently bundled with mass-market word processors have developed rather a bad name for precipitating crashes of the host software.
Text editor integration
This relates to the ease with which actions based on advice given by a checker can be incorporated into the relevant document, and
On-line help
The quality of on-line help as it affects the usability of the system must be considered as a counterbalance to the ease with which the system can be used without any training.
Printed documentation
As above.
Rule selection
Simply turning on or off existing rules is the most that many grammar checkers allow, but this may not provide sufficient flexibility. Others allow the definition of sets of active rules which could be suitable for different user groups - students, journalists technical writers, etc. At least one version of a popular grammar checker provided a fiendishly complicated and unusable regular expression language that could refer to the part of speech tags supplied by the analysis; apart from the usability disaster, it is doubtful that many end-users would possess the linguistic background to adequately express new grammar error rules in such a formalism. The issue of customisability for grammar checkers, then, might, as suggested above under the discussion of maintainability, be more relevant to dedicated or "generic" systems, where customisations might need to be supplied by more specialist staff than the end-user.
Personal dictionary maintenance
Grammar checkers typically have integrated spelling checkers and usage checkers so that all proofreading can be done in one pass. Spelling checkers require personal dictionaries for valid words that are not included in the system dictionary. Usage checkers require personal dictionaries to override and supplement usage patterns for specific words (including problem discussions and suggested replacements). If a grammar checker lets users work with different named sets of rule settings, these may be combined with the spelling or usage personal dictionaries or kept in a separate file.
For spelling checkers, sub-attributes of recall were presented for various kinds of text element for which we have reason to believe spelling checker coverage performance might vary, such as closed-class words, technical terms, productive sub-vocabularies, and so on. The equivalent for grammar checkers would be the various grammatical and lexical contexts according to which grammar checker performance is likely to vary. Some sort of taxonomy of the complexity of linguistic context should be used, along the lines of the categories used in TSNLP (Balkan et al (1995), Oepen et al (1995), Estival et al (1995)). It seems likely that different degrees of complexity of syntactic context, or different numbers of unusual lexical items which can't be recognised, will affect the recall as we have defined it here, but it should be borne in mind that it is probably relatively easy to simply turn off reporting at levels of complexity that interfere with performance.
A provisional error taxonomy
A certain amount of work has been carried out on grammatical errors occurring in different languages, but a prerequisite for developing a comprehensive test package for grammar checkers is a classification of different categories of grammar error. To be valid in our model such a classification of grammar errors would ideally be developed from detailed corpus analysis by properly qualified informants. This of course presupposes the existence and availability of large (enough) corpora of unproofed texts of various kinds to ensure that we treat genuinely occurring errors. Such a classification is not necessarily the same as the sorts of errors which grammar checker manufacturers claim to cover.
Particular types of grammar error are, of course, specific to particular languages. However we can generalise some top level categories which apply to the languages treated by grammar checkers, for example,
* Agreement errors
* Subcategorisation errors
* Word order (phrase structure errors)
In the following we consider each of the categories in turn.
Agreement errors
Once we go below the highest level of classification certain sub-attributes will only apply to some of the languages we treat. So to take the example of agreement errors, we have the following sub-attributes
* Determiner Noun Agreement (DA, EN, IT)
* these book - number disagreement
* en hus - gender disagreement
* Adjective Noun Agreement (DA, IT)
* stor huse - number/gender disagreement
* Subject Verb Agreement (EN, IT)
* the dogs barks - person/number disagreement
* Subject Adjectival Predicate Agreement (DA,IT)
* hunden er gammelt - gender disagreement
* la radio è acceso - gender disagreement
Thus determiner noun agreement applies in Danish, English and Italian, but even so, the attributes in which they must agree differ. In English, determiners and nouns must agree in terms of number, whilst in Danish and Italian they must also agree in terms of gender. Adjective noun agreement applies only in Danish and Italian, where, in Danish, the form of the adjective depends not only on the number and gender of the noun but also on the definiteness of the noun phrase as a whole. It is clearly not possible to define a complete multilingual taxonomy of grammar errors. However, we feel that a higher level taxonomy which can act as a prompt to defining the error taxonomy for a specific language is a useful tool.
Nevertheless, such a grammatically defined taxonomy does not indicate anything about sources of errors, and it is also important to define error types in terms of their source, in much the same way as we did for spelling errors. So for example, agreement errors could arise from phonological sources.
For example there is confusion between the use of the indefinite quantifiers nogle and nogen which for most Danish speakers have the same pronunciation. The resulting problem may be one of number agreement. In declarative sentences, when they are used as nouns nogle means more than one whilst nogen refers to one. When they are used as adjectives, nogen must always be used with (common gender) mass nouns, whilst nogle is used with count nouns. In addition to the question of number agreement there are differences in polarity such that only nogen occurs in interrogative, and negative sentences. They can thus be related to English any or some. E.g.,
Der lå nogle aviser på bordet.
(There were some newspapers on the table.)
Der var nogen modstand mod forslaget.
(There was some resistance to the proposal.)
Der lå ikke nogen aviser på bordet.
(There were not any newspapers on the table.)
Thus the following sentences are grammatically incorrect
* Der lå nogen aviser på bordet.
(There were any newspapers on the table. )
* Er der nogle hjemme?
(Are there some home?)
Subcategorisation errors
Here we classify subcategorisation errors according to the subcategorising predicate with subtypes of error according to the type of argument which is subcategorised for:
* Noun Subcategorisation Errors
* missing complement
* incorrect complement type
* preposition/complementiser choice
* Verb Subcategorisation Errors
* missing complement
* incorrect complement type
* preposition/complementiser choice
* confusion of related transitive and intransitive verbs
* Adjective Subcategorisation Errors
* missing complement
* incorrect complement type
* preposition/complementiser choice
* Preposition Subcategorisation Errors
* missing complement
* incorrect complement type
So for nouns, verbs, and adjectives we allow for the possibility of three different types of error associated with subcategorisation. A complement may simply be missing, e.g.
* He told that he would arrive late tomorrow.
(He told me that he would arrive late tomorrow.)
or of the wrong type:
* I enjoy to swim.
(I enjoy swimming.)
In some cases it may not be clear which of the above two types of error applies as, for example, in the following quite common error made by second language speakers of English:
* The system enables to exchange information
where the verb enable subcategorises either for a noun phrase, or a noun phrase followed by an infinitive clause (i.e., an object control construction), thus it is not possible to say whether the above error is due to a NP being omitted or that the complement is of the wrong form (i.e. a clause instead of an NP). Any of the following could be correct:
The system enables the exchange of information.
The system enables information to be exchanged.
The system enables one to exchange information.
Certain predicates subcategorise for specific lexical items (typically prepositions or complementisers) e.g. depend on, dreje sig om (be concerned with) dipendere da (depend on). Other cases can be more complex in that the choice of a preposition depends on the type of argument it introduces, so for example the Danish verb at beslutte sig (to decide) takes the preposition til to introduce an infinitival complement, but the preposition for to introduce an NP complement, e.g.
Han besluttede sig til at gå på MacDonald's.
(He decided to go to MacDonald's.)
Han besluttede sig for en Quarterpounder.
(He decided on a Quarterpounder.)
Subcategorisation errors would typically be made by non-native speakers of the languages in question. However subcategorisation errors can also be committed by native speakers.
In addition under verbs we have included errors arising from the confusion of closely related transitive and intransitive verbs such as lie and lay in English or hang and hængte in Danish, where the first in the pair is intransitive and the second transitive:
* Why don't you go and lay down?
(Why don't you go and lie down?)
* Frakken hængte på knagen.
(The coat hung (transitive) on the peg).
Errors arising from phonologically similar words can also result in subcategorisation errors. In some types of construction in Danish there is confusion over whether one should use the conjunction og (and) or the infinitive marker at, when conjoining two clauses. As with nogen and nogle, for many Danish speakers, these two words are pronounced the same. The error is not localised, in that the whole complex sentence must be analysed in order to determine whether there is an error or not:
* Jeg vil forsøge og være hjemme kl. 18.
(I will try and be home at 6.)
In this case the correct form will include the infinitive marker at i.e.
Jeg vil forsøge at være hjemme kl. 18.
(I will try to be home at 6.)
The resulting error here is one of subcategorisation because forsøge subcategorises for an infinitive phrase. However the situation is complicated because it is not the case that infinitives must always be preceded by at instead of og since og can also occur with an infinitive clause when there is ellipsis of the auxiliary - e.g.
Vi vil tage hjem og hvile os.
(We want to go home and rest.)
Word order errors
Under this type of error, we predict that often subtypes of error will be highly language specific. So, for example, in Danish, canonical word order differs between main and subordinate clauses. In particular, the position of adverbs differs, so that in main clauses an adverb will occur after the subject and finite verb, whereas in subordinate clauses an adverb must occur between the subject and finite verb. So the following is grammatically incorrect:
* Man jo tænker mere på den danske dronning end den engelske
(One, you know, thinks more of the Danish queen than the English one.)
In this example, the adverb jo (you know) occurs before the finite verb even though it is in a main clause. This is a quite frequent error type which is attributed not to Danish writers' lack of knowledge of the rules governing adverb placement, but rather to the writer having first written such a sentence as a subordinate clause and afterwards deciding to change it to a main clause and forgetting to move the adverb. Thus in this case we have an error due to the mechanical process of editing text rather than conceptual problems on the part of the writer.
Thus for Danish there may be specific subtypes of word order problems such as:
* Main/subordinate clause word order
However other subtypes of word order problem apply to more than one language. For example in Danish, subject-verb inversion occurs when the first element of a clause is not the subject e.g.,
Jeg købte en bil.
(I bought a car.)
I går købte jeg en bil.
(Yesterday, bought I a car.)
However, a similar case of inversion does occur in English when the first element in the clause is negated,
Never before have I read such utter rubbish.
and this is known to create problems for second language writers of English, although this is much more restricted than inversion in Danish. Thus, a sub-attribute which is shared between Danish and English would be
* Subject-verb inversion
Similarly problems occur within verbal groups and the choice of the correct form of a verb. For example, in Danish as a general rule, present tense forms of verbs end with 'r' whilst infinitive forms are the same except that they lack the final 'r'. A rather frequent error occurs in which an auxiliary verb is followed by a present tense form instead of an infinitive e.g.:
* Charlottenborgs chancer for at kunne præsenterer noget ordentligt.
(Charlottenborg's chances of being able to present something reasonable.)
Once again it is claimed that this is hardly an intentional error, although it is common. In such cases it is not clear whether the writer first intended to have a simple tense and then changed this to a compound tense (modal or auxiliary + infinitive) and forgot to change the form of the main verb, or whether it is a mechanical typo or a spelling error (another example of the well-known problem with r in Danish which we described in our work on spelling checkers).
The tentative taxonomy presented above is defined in objective grammatical terms and itself makes no claims about the possible sources of the errors. We have tried to provide concrete examples to indicate how different causes can create grammatical errors. Some of the example errors given above are common second language errors, whilst others are often committed by native speakers and can be caused by a number of factors such as imperfect knowledge of the rules of the language, mechanical text editing errors, or phonological confusions. Thus, in addition to a purely syntactically based taxonomy of errors, a classification of errors according to their source or cause, derived from requirements analysis, is also necessary. Such classifications necessarily cut across the purely grammatical classification outlined above.
In order to be properly informative, the precision attribute should probably be subdivided, like the recall one, for types of grammatical structure, in this case the type of grammatical structure in which given errors appear. Checker precision (successful identification of errors) is clearly worse with longer and more syntactically complex sentences; this is to some extent the counterpart of the factors affecting recall above, in that a strategy of only reporting errors when positively identified will lead to fewer reports in more complex contexts where the processes are less reliable. Reporting these differences may be very important for certain classes of writer/end-user combinations; for one, it might be that errors only really occur in long and complicated sentences, and so it is important to know if the checker does not in fact help much with these; on the other hand, particularly where poor writers or second language users are concerned, good performance on simple sentences may be more important than any coverage of more complex ones. Accordingly, the main difference between our precision sub-attributes for spelling checkers and grammar checkers is that precision must be taken to combine variation in error types and variation in contexts for grammar checkers.
This makes it necessary to understand what levels of linguistic terminology are suitable for the intended end-user, and how far example-based aids to diagnosis/generation would be necessary.
Positive coverage
Given a list of grammatically correct sentences the basic measure could be a simple percentage of correctly accepted sentences. The list of correct sentences would be subdivided into different lists according to the grammatical construction covered and the complexity of the sentences. The basic measure for each list would then be:
number of sentences accepted / total number of correct sentences
expressed as a percentage for each list. Assuming the lists of correct input are constructed according to levels of syntactic complexity along the lines of TSNLP syntactic contexts (call them here A, B, C, etc.) the measure for each list representing a syntactic context would be represented in terms of percentages, e.g.
1. % of correctly accepted sentences in context A
2. % of correctly accepted sentences in context B
3. % of correctly accepted sentences in context C
Then, there are two possible ways of calculating an overall measure for positive coverage. Either the user is more interested in positive coverage in one or other context than another, for example complex syntactic contexts in which many grammar checkers perform less well than in more simple contexts. In such cases different weightings are assigned to the measures for each context and a weighted mean score is derived, in a similar way to that applied to common word coverage in spelling checkers. On the other hand, a user may not be interested in performance in different syntactic contexts and a simple aggregate score can be calculated.
So far, in measuring positive coverage we have taken the sentence as the basic unit for testing. However this may seem to be a somewhat simplistic measure since it does not take into account cases where the checker wrongly identifies more than one grammar error in a sentence. In the case of positive coverage (i.e., how many sentences are correctly recognised) this is not such a great problem. However in the case of false flagging, which we turn to next, it is of greater importance.
False flagging
In our model of spelling checker evaluation we considered the basic measure of false flagging to be simply the inverse of the measure for positive coverage. Thus, for example, if the score for positive coverage of a spelling checker on a particular list of words was 90% then the score for false flagging was 10%. Indeed, this is a measure that can also be provided in the case of grammar checkers, so that one measure of false flagging is simply the inverse of the measure for positive coverage.
However, since this deals only with the number of sentences incorrectly flagged as containing at least one error, this does not really provide an accurate enough measure of the level of false flagging by a checker, since more than one error may be detected in a single sentence. To be able to compare different checkers we also want to provide the customer with more precise information on the level of false flagging. Thus we propose that, similarly to the proposal for false flagging in spelling checkers, naturally occurring running texts should also be used as test materials. However unlike the case of spelling checkers, these would have to be unproofed texts, which contain grammatical errors and then what we propose for this extra dimension of false flagging would in fact be a precision (rather than a simple recall) measure in which we measure the rate of false flaggings as a percentage of the total number of flaggings for a particular text:
number of false flaggings / total number of flaggings
The basic measure for error coverage then, is the number of errors correctly identified as a percentage of the number of errors presented to the checker. For each sub-attribute this is measured at all the levels of complexity. So, for example, the sub-attribute of determiner noun agreement would have the following three measures:
1. % of correctly flagged determiner noun agreement errors in context A
2. % of correctly flagged determiner noun agreement errors in context B
3. % of correctly flagged determiner noun agreement errors in context C
Now, given these basic measures, it is possible to derive more complex measures along the two dimensions of error type and syntactic and lexical complexity. The choice of complex measure to be derived would depend on particular user requirements. Thus, an overall measure of the checker's performance on a particular sub-attribute regardless of the syntactic context in which they occur can be derived by summing the values for each context and then deriving an average score. In cases where requirements analysis yields a clear preference for a grammar checker to catch errors in particularly complex contexts then weights could be assigned to different contexts and a weighted score obtained. In addition to measures for sub-attributes of precision, an average measure of performance based on different contexts of complexity can also be derived (by averaging the scores for each sub-attribute within each context) to give the following sort of measure:
1. average % of correctly flagged errors in context A
2. average % of correctly flagged errors in context B
3. average % of correctly flagged errors in context C
In the domain of spelling we have a simple model of a spelling error as consisting of two parts: an illegal word form and the intended legal word. One could, of course define a model of grammatical errors which mirrors that for spelling errors, i.e. consisting of two parts: an illegal construction and the intended legal text. However, unlike in the case of spelling, it is not feasible to have a finite list of correct sentences or phrases for the system to consult (as with the dictionary of a spelling checker).
The extra complexity of the grammar checking task (with respect to spelling checking) is also reflected in the extra complexity of grammar checking systems. Spelling checkers, in addition to indicating the presence of a spelling mistake, generally provide the user with one or more suggested replacements which she can choose to insert into her text. Grammar checkers on the other hand, as well as indicating the presence of a grammatical error, attempt to diagnose the source of the error and offer advice as well as a possible replacement construction.
In many cases the checker could not be expected to offer a replacement but rather diagnose a certain type of error and give some explanation in order to help the user to correct the error. The quality and usefulness of any such advice and explanations cannot be automatically checked against some predetermined "correct advice", instead it must be turned over for manual inspection and scoring. It also seems doubtful that the correct diagnosis of a grammatical error could necessarily be automatically checked since this may depend upon the special terminology used by a particular system.
As with spelling checkers, it is necessary to define not only a grammatical model of the language being checked but also a model of grammatical errors pertaining to a particular set of users and, based on empirical research, determine the relative importance or weight that different sub-attributes of grammar errors should have. Although there may be some mechanical errors such as word doubling, which could be quite easily generated automatically from a given text, linguistically based errors would not be easy to generate automatically, requiring both a comprehensive grammatical model to analyse texts as well as a model of grammatical errors.
Whilst it seems that test suites for grammar checkers cannot successfully be generated automatically in the same way as for spelling checkers, this is not to say that generating them "by hand" should be much less rigorous.
Test suites for positive coverage (and false flagging)
We suggest two ways of constructing test suites for positive coverage:
1. Naturally occurring texts which have been proofread. The text type would depend on the user requirements.
2. A list of correct sentences which cover all the constructions which the checker is being tested on, embedded in various levels of syntactic and lexical complexity. (These will be the converse (i.e. list of "correct" versions) of the sentences constructed for error coverage).
In other work on testing grammar checkers (cf. EAGLES Evaluation of Natural Language Processing Systems, Final Report), it is proposed that a set of "traps" to catch out the checker should also be defined in order to check false flagging. However, the nature of these traps seems to be somewhat dependent upon knowledge of how a particular grammar checker works (either this is inferred from observed behaviour or the algorithms themselves are known). This seems to be somewhat contrary to our black box approach, and it is not clear how rigorously one could define an objective enough test to be applied to several different grammar checkers. Another shortcoming in this approach is that there would be a tendency to base testing on those things which grammar checkers are known to be able to do. Therefore it is not proposed here.
Test suites for error coverage
As indicated above, constructing test suites for error coverage involves the construction of sentences of varying syntactic complexity containing errors of particular types. The development of a typology of such errors involves extensive corpus analysis of existing unproofed texts produced by different types of user. In addition to identifying error types, statistical information on the frequency of different error types according to different user profiles will produce information which can be used in assigning weights to measures of different sub-attributes.
In addition to such constructed test suites, some "naturally occurring" errorful texts could also form part of a test suite. Texts would be marked up with errors by some suitably qualified informant, and this corpus would then be checked.
The effort involved in liaising with the five projects turned out to be more than had been estimated, and after the mid-term review it was decided to concentrate on two, who had shown themselves to be enthusiastic about collaboration with TEMAA. The choice of the two projects was felicitous. One of the two, COBALT, had started work on evaluation before the EAGLES interim report was easily available, and had therefore worked independently of any EAGLES or TEMAA input, taking inspiration primarily from the methods and metrics classically used in information retrieval and, in particular, in the ARPA funded TREC conferences. The second, RENOS, had used the EAGLES interim report as a way to structure thinking about evaluation. It was thus possible to carry out a two-fold partial validation of the EAGLES/TEMAA proposals, by comparing them with what had happened in practice in COBALT and by asking if they had been useful to RENOS.
COBALT falls into the general class of message routing systems. Brief articles in the financial domain are taken from a wire service, analysed and identified as of interest or not to either of two classes of users; stockbrokers and financial analysts. These two user communities have different needs, which are reflected in the way the system is designed. Briefly, a first system component tries to do a very rapid classification based on a shallow analysis of the text which is subsequently filled out by modules which deepen that analysis. The project was therefore interested in evaluation of the prototype system as a whole, in evaluation of the individual components, in evaluation of the integratability of the components, and in evaluation of how well the prototype would scale up to become a fully operational system.
The reader is referred to TEMAA Deliverable D15 for a detailed account of an attempt to recast the evaluation methods proposed within the COBALT project in terms of the general framework. Here we shall simply remark that where the COBALT proposals were well-worked out and were clearly and precisely defined, it proved to be very easy not only to re-express them in framework terms but also to identify and discuss problem areas with the project team. (For example, one particular measure was proving difficult to define and to interpret in a fully satisfactory way). This was taken as confirmation both of the COBALT proposals in those areas and of the framework proposals, as well as being an indication that the framework proposals might be useful to other projects. In the case of those modules where the COBALT evaluation proposals were less well-defined, it was felt that being able to re-think them in the light of the framework would prove helpful. This point is worth emphasising a little: where COBALT had been able to make extensive use of previous thinking about evaluation in the IR domain, this had proved very helpful. TEMAA hopes to have built on such previous work in order to provide a more structured way of thinking about measures and methods. If the COBALT project had had available a TEMAA-type PTB already containing methods that could be adapted to their specific needs, their work would have been made easier and a certain amount of re-duplicated effort would have been avoided.
There was one area though where neither COBALT nor the framework proposals had anything much to say. This was on the question of how to assess whether the prototype would scale up to operational system size. This question is critical for almost every project, but there is very little in the literature or in other work on evaluation outside TEMAA and EAGLES: the ARPA evaluation programmes, for example, do not tackle the question at all, and the Japanese efforts on the evaluation of machine translation systems and aids similarly largely ignore it. It would therefore seem one obvious area for future work on evaluation.
RENOS is concerned with reducing noise and silence when retrieving documents from a full text documentary data base of legal texts by making use of an indexing method to allow texts to be retrieved on the basis of concepts rather than words. The basic index structure is an intelligent inverted list, whose components are a Conceptual Hierarchical Network, a Morphological Lexicon and a Constituent Grammar for legal terms.
Once again, the project is concerned with the evaluation of the prototype system as a whole, in this case under two perspectives, that of document classification where the standard against which RENOS performance is to be compared is expert manual classification, and that of document retrieval, where the focus of the evaluation is on determining what gains in search proficiency result from the RENOS search facilities. The project is also concerned with evaluation of the individual components of the system, with the main emphasis being on their functionality, although evaluation of maintainability and portability to different target domains were pursued at least far enough to obtain qualitative results.
The use of the ISO 9126 quality characteristics in the wording of the last paragraph already makes it clear that the RENOS project team made a conscious effort to follow the general framework in working out their evaluation methods. This is reflected in the project evaluation guidelines which are summarised in TEMAA Deliverable D15. All that needs to be added here is that the RENOS project team had clearly found it both useful and stimulating to be able to use the framework, and that discussion of the evaluation methods proposed was much facilitated by the sharing of a common background. As with the COBALT project, discussion brought out one general problem that deserves some attention in later work. It was hard to see how gains in search proficiency could be measured except through asking a statistically significant number of representative end-users to carry out searches with and without the RENOS improved search facilities. Not only would this be expensive and difficult to organise, but it raises the general issue of the validity of measures which rely on human aid to obtain a value. The importance of this issue and the difficulty of finding a satisfactory solution to it is emphasised by the failure of the ARPA funded machine translation evaluation programme to solve it. (See White et al, 1994).
In summary, the TEMAA experience with the two information projects tends first to confirm the utility in general of having a structured way of thinking about evaluation available. Secondly, it tends to suggest that although the general framework as put forward by the EAGLES group and further refined by TEMAA remains at a fairly high level of abstraction, and still needs more exemplification and validation through practical application to the evaluation of different kinds of systems in a variety of application areas and using a variety of different viewpoints, it is on the right general lines and is a good start.
Quality Characteristics serve as a set of headings to organise a set of attributes which encapsulate the quality of a system to be tested where the meaning of quality is determined by both the type of system on one hand, and the users of the system, on the other hand. The variable elements of set-ups that affect the quality requirements of different customers are also taken into consideration. At this, highest, level of granularity, grammar checkers and spelling checkers can be treated as substantially identical. For both, the roles in the basic task set-up are the same.
The list of quality characteristics for the two types of system is the same. However, given the differing complexity of the two tasks and the necessarily greater complexity of grammar checkers in comparison with spelling checkers, various quality characteristics may have a different interpretation, either in the importance to be attached to them or the composition of their reportable attributes. Under Functionality of grammar checkers, for example, we include both Problem Checking (which mirrors the functionality characteristic in spelling checkers), and a separate subattribute Correction Support reflecting the greater importance of explanatory or educational material in helping the user diagnose and correct grammar errors.
Similarly, questions of reliability and efficiency become more crucial for grammar checkers than spelling checkers. Grammar checkers, comprising a greater number of components and functions, and also requiring relatively heavy computational resources, are more likely to crash or run slowly than spelling checkers. The other aspect of reliability, which is concerned with the checker consistently exhibiting the same behaviour when confronted with the "same" type of error, may be harder to define in grammar checkers, since there may be a mismatch between users' perceptions of classes of errors and the system's classification of errors. Similarly, customisability in spelling checkers revolves around the customisation of dictionaries (adding specific lexical items) whilst in grammar checkers, it would be concerned with the ability to add quite complex rules, and the possibility of turning on or off sets of existing rules.
Reportable functionality attributes
The top level reportable attributes of grammar checkers that relate to the problem checking aspect of functionality bear a good deal of resemblance to those for spelling checkers, because of the basic similarities between the two tasks. Below that level, however, different classifications of the types of error must be made. In the case of grammar checkers there is an open question about how far a given level of such a classification can be made multi-lingual; if we think about the purpose of our work, which is more to provide a framework or cook-book to provide support and guidance to someone attempting to construct some specific evaluation, the purpose of such a cross-linguistic taxonomy of error types is clearer, and in fact less restrictive; if there are enough places in such a taxonomy to jog the mind of the evaluation developer, this is more important than its exhaustiveness or being entirely correct.
The top level attributes for both spelling and grammar checkers are recall, precision, and suggestion adequacy. The major difference between spelling checkers and grammar checkers for the purposes of devising similar lists of reportable attributes is that the operation of a spelling checker always involves pairing a proposed error word with a specific suggested replacement word, or list of words, or with nothing, while the response of grammar checkers may provide a range of different suggestion forms, from a literal replacement, suitable for incorporation into the text directly, to various levels of "recipe" for constructing a replacement, which demand skills in the end-user of diagnosis and text construction that go beyond the simple recognition of the intended text which is adequate for using a spelling checker.
Measures and methods
The measures for recall and precision in both types of checkers are fundamentally the same in as much as they reflect the proportion of either correctly accepted items from a list of correct items (recall) or correctly flagged errors from a list of erroneous items (precision). This proportion is either expressed as a simple percentage or a weighted mean score.
The methods for deriving these measures, however, differ quite radically. For spelling checkers it is possible to largely automate both the creation of test suites and testing of specific systems. For grammar checkers, on the other hand, where the test suites must reflect an interaction between syntactic constructions being tested and the (syntactic or lexical) complexity of the constructions in which they are embedded, automatic generation of test suites is not feasible. Similarly, given the complex nature of the output of a grammar checker, automation of testing is also not feasible.
Despite these differences the TEMAA framework, at its highest level, can also be applied to information extraction systems. The quality characteristics are the same for all three application types. Since the task set-up is radically different from that for checkers, it is not surprising that the reportable attributes defined were very different, reflecting the importance of user profiling in determining reportable attributes (as borne out in the COBALT experience). [1] However, as a matter of conveniency and efficiency it is also very useful for a native speaker to be able to substitute a valid spelling by a touch of a key.
[2] The following magazines were used: Haven, Folkeskolen, Arbejdsgiveren, Sygeplejersken, Ingeniørens Ugeblad, Dansk Jagt.
[3] We use the word "term" to indicate that the list contains simple words as well as compounds.
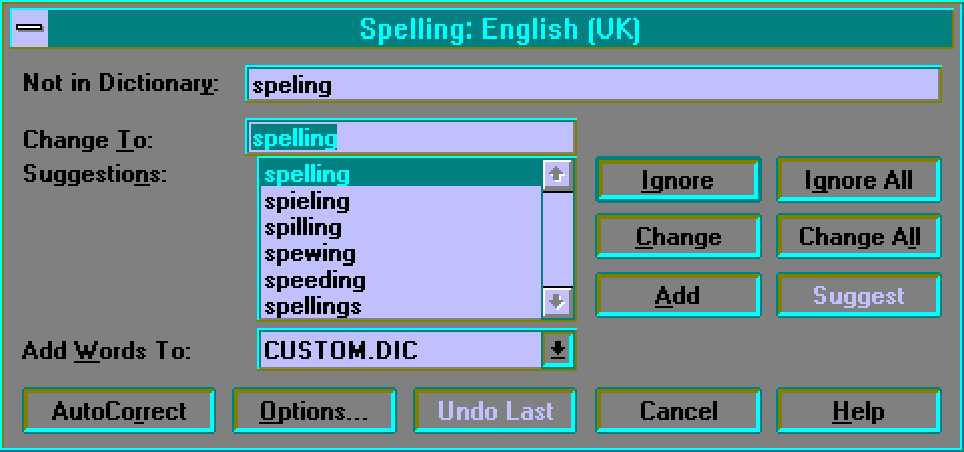{kind=link}