



The EAGLES work took as its starting point an existing standard, ISO 9126, which is concerned primarily with the definition of quality characteristics to be used in the evaluation of software products. ISO 9126 sets out six quality characteristics, which are intended to be exhaustive. From this it follows that each quality characteristic is very broad. The six quality characteristics are functionality, reliability, usability, efficiency, maintainability and portability. We shall not recapitulate all six here, but will give the ISO definitions of two which have been of special importance in EAGLES and TEMAA work as illustrative examples. Each ISO definition is accompanied by notes, which are often critical to the interpretation of the definition itself. We therefore also give the notes.
"4.6 Functionality
A set of attributes that bear on the existence of a set of functions and their specified properties. The functions are those that satisfy stated or implied needs.
Notes:
1. This set of attributes characterises what the software does to fulfill needs, whereas the other sets mainly characterise when and how it does.
2. For the stated and implied needs in this characteristic, the note to the definition of quality applies (see 3.6)."
Since this note (3.6) will prove critical to later argumentation, we reproduce it here:
"NOTE: In a contractual environment, needs are specified, whereas in other environments, implied needs should be identified and defined. (ISO 8402: 1986, note 1)."
A second quality characteristic that has been important withinTEMAA is usability.
"4.3 Usability
A set of attributes that bear on the effort needed for use, and on the individual assessment of such use, by a stated or implied set of users.
Notes:
1. "Users'' may be interpreted as most directly meaning the users of interactive software. Users may include operators, and users and indirect users who are under the influence of or dependent on the use of the software. Usability must address all of the different user environments that the software may affect, which may include preparation for usage and evaluation of results.
2. Usability defined in this International Standard as a specific set of attributes of software product differs from the definition from an ergonomic point of view, where other characteristics such as efficiency and effectiveness are also seen as constituents of usability."
A key point here is that quality characteristics are the top level of a hierarchical organisation of attributes: each characteristic may be broken down into quality sub-characteristics, which may themselves be further broken down. Specific evaluations or specific views of software quality may imply that some attributes are considered to be more important than others. ISO mentions the views of the user, the developer and the manager. The manager's view is quoted here in illustration.
"A manager may be more interested in the overall quality rather than in a specific quality characteristic, and for this reason will need to assign weights, reflecting business requirements, to the individual characteristics. The manager may also need to balance the quality improvement with management criteria such as schedule delay or cost overrun, because he wishes to optimise quality within limited cost, human resources and time-frame''.
The quality characteristics are accompanied by guidelines for their use. As we shall see, each attribute is associated with one or more metrics, which allow a value for that attribute to be determined for a particular system. As ISO 9126 points out:
"Currently only a few generally accepted metrics exist for the characteristics described in this International Standard. Standards groups or organisations may establish their own evaluation process models and methods for creating and validating metrics associated with these characteristics to cover different areas of application and lifecycle stages. In those cases where appropriate metrics are unavailable and cannot be developed, verbal descriptions or 'rules of thumb' may sometimes be used''.
The guidelines nonetheless suggest an evaluation process model, which breaks down into three stages. First comes the quality requirement definition, which takes as input a set of stated or implied needs, relevant technical documentation and the ISO standard itself and produces a quality requirement specification. The second stage is that of evaluation preparation, which involves the selection of appropriate metrics, a rating level definition and the definition of assessment criteria. Metrics, in ISO 9126, typically give rise to quantifiable measures mapped on to scales. The rating levels definition determines what ranges of values on those scales count as satisfactory or unsatisfactory. Obviously, since quality refers to given needs, which vary from one evaluation to another, no general levels for rating are possible. They must be defined for each specific evaluation. Similarly, the assessment criteria definition involves preparing a procedure for summarising the results of the evaluation and takes as input management criteria specific to a particular environment which may influence the relative importance of different quality characteristics and sub-characteristics. This definition too is therefore specific to the particular evaluation. The final stage is the evaluation procedure, which is refined into three steps: measurement, rating and assessment. The first two are intuitively straightforward: the selected metrics are applied to the software product and values on the scales of the metrics obtained. Subsequently, for each measured value, the rating level is determined. Assessment is the final step of the software evaluation process, where a set of rated levels are summarised. The result is a summary of the quality of the software product. The summarised quality is then compared with other aspects such as time and cost, and the final managerial decision taken based on managerial criteria.
In line with this, one very early piece of work within TEMAA was an extremely informal survey of a small sample of users of spelling checkers for different languages . The survey, although it made no claims whatever to statistical significance or to being exhaustive, did give an indication of the variety of users and led to attempts to systematise user modelling in terms of defining the tasks to be done and the roles played by different agents in fulfilling the tasks. This survey was complemented by a survey of the literature on evaluation of spelling checkers.
Other survey work fed into work on how the ISO 9126 quality characteristics apply in the context of defining an evaluation of spelling checkers and of grammar checkers. One important extension has consequently been made here too. The ISO characteristics are:
* functionality
* reliability
* usability
* efficiency
* maintainability
* portability
Language engineering products have one particular characteristic which does not fit very comfortably under any of these characteristics with their definitions as given in ISO 9126. A language engineering product nearly always has to be modified to fit the particular customer's special requirements, either by changing its behaviour to fit his needs or by enlarging its coverage of the language in question. With spelling checkers, for example, users are often given the option of adding items to a personal dictionary. With grammar checkers, users may set parameters to determine what should be considered too lengthy a sentence, or specify lists of words that for some reason or another are considered undesirable. These are quite simple examples: it is possible to find more complex and more sophisticated examples of needing to fit a product to a user's environment which can be of critical importance in determining whether a product is acceptable or not. Whilst it is true that the ability to make changes could be forced in as a sub-characteristic under the ISO 9126 definition of maintainability, this seems rather counter-intuitive. Thus, given the importance of a user being able to adapt a product to suit his own needs, we have chosen to promote what we have called "customisability" to the status of a quality characteristic in its own right.
We noticed in the section on ISO 9126 that quality characteristics are the top level of a hierarchy: each can be broken down into a set of attributes (called in TEMAA work "reportable attributes"), for each of which one or more measures and methods are defined whereby, when any particular system is evaluated, a value for each attribute can be assigned for that particular system. The hierarchy can go as deep as is required: each attribute can in its turn be broken down into sub-attributes, for which measures and methods are defined, and so on.
Later sections of this report take up the instantiation of quality characteristics through the choice of reportable attributes and the definition of measures and methods in more detail.
The description of the framework given so far is in very informal terms, as is necessarily the case with a natural language description. If we want to make definitions precise, and especially if we want to automate as much as possible of the evaluation process, finding an appropriate formalisation is of critical importance.
The immediately next section of this report provides a description of the results achieved by the project in providing a concrete instantiation of the general framework in the form of a parameterisable test bed: a software implementation which contains formal descriptions of systems or products and of characteristics of users, together with specifications of metrics and measurement methods. Parameters allow the needs of a specific user to be reflected as constraints and weightings to be applied to the results of measurements. It should be noted though that not all metrics are automatable. In many cases, the test bed produces instructions for how a human should proceed in order to obtain a measurement for some attribute singled out as pertinent.
As we have already remarked, the parameterisable test bed is of necessity based on a formal definition of evaluation and on formal descriptions of user characteristics and of system characteristics. In line with much current work in computational linguistics, the description is in terms of features, made up of attribute/value pairs. The definition of features may come either from a consideration of the implied needs of users or from considering the characteristics of systems which already exist. Attribute/value pairs are intimately related with the metrics used to determine the values. We have already noted that whilst ISO 9126 regards metrics as ideally leading to quantifiable measures, it is recognised that this cannot always be the case. As well as metrics based on quantifiable measures, often called "tests" in EAGLES and in TEMAA, EAGLES and TEMAA also recognise "facts" - attributes whose value is simply a fact such as the language dealt with by a spelling checker, and binary and scalar attributes, some of which may explicitly involve subjective human judgement. Thus attributes are typed by the kind of value they may accept. The next section goes into more detail and gives a more formal account of the machinery we have used.
It should be noted that although the parameterisable test bed described in this report contains only descriptions and metrics relevant to authoring aids, we believe that it provides the skeleton of a much more general mechanism, which could subsequently be extended to include whole libraries of user descriptions, types of product and well-defined metrics. The ISO 9126 standard quite deliberately leaves aside any discussion of how metrics are to be created or validated. Clearly, since TEMAA is involved in practical application of the general framework, such questions cannot be neglected. In particular, both measures and the methods used to obtain a measurement must be valid and reliable; that is, a metric should measure what it is supposed to measure, and should do so consistently.
The notions of validity and reliability as used within TEMAA and EAGLES draw on work in the social sciences and in psychology. Although there are several conceptions of validity to be found in the literature, they all essentially fall under one of two broad categories: internal (or contents) validity and external (or criteria based) validity. Internal validity is achieved by making sure that each metric adequately measures an appropriate attribute of the object to be evaluated. Internal validity is assessed by the judgement of experts. External validity is determined by calculating the coefficient of correlation between the results obtained from applying the metric and some external criterion.
A couple of examples will help to make this more concrete. Reading tests are often administered to primary school children to determine whether they can read as well as an average child of the same age. The child is required to read aloud a specially constructed text, which makes use of the vocabulary which it is considered a child of a specific age should be able to deal with. This test relies on internal validity. Whether the vocabulary chosen is or is not well-chosen is judged by experts on the reading skills of children.
Another test frequently administered to school children is an IQ test. The usefulness of such tests has often been the subject of contention. A frequent type of argument to be found is based on the notion of external validity: the results of the tests are shown to correlate well (or badly) with later success in academic examinations, for example, or with higher income levels in middle age.
A metric is reliable inasmuch as it constantly provides the same results when applied to the same phenomena. Reliability can be determined by calculating the co-efficient of correlation between the results obtained on two occurrences of applying the metric.
Considerations of validity and reliability are not always so clear-cut as they have been made to seem in the above discussion, particularly when the evaluation is concerned with products treating a phenomenon as complex as language, and where human intervention is needed sometimes to obtain a measurement. More detailed discussion of particular metrics will raise further questions. But the goal to be aimed at is clear.
A PTB would have several components, to be described below. Some were implemented in TEMAA; some of these are specific to spelling checkers, others are more generally usable. In our opinion, a major goal for future evaluation-related work on evaluation would be to continue on this track, i.e. the design and use of a PTB.
In this section, we first make some notions of the ISO document (see above) more precise. We then give an abstract definition of a PTB. A more detailed description is given in chapter 4. The actual programs and their documentation have been delivered separately, as TEMAA deliverable D17.
To evaluate is to determine what something is worth to somebody. We describe evaluation as a function relating objects and users to something we will call utility. Utilities can sometimes be expressed in financial terms, but that does not concern us here. The important thing is that utilities represent a consistent preference relation among the items utilities are assigned to.
We then look at the nature of the descriptions of objects, found in e.g. consumer reports. Some useful primitives are introduced. The formal machinery is taken from the world of feature structures, well-known to computational linguists.
We then define some notions relevant to evaluation in terms of these primitives.
The basic evaluation function
To evaluate is to determine what something is worth to somebody. We can summarise this in the following function:
O U V
where
O is a set of objects
U is a set of users
V is a set of values
V represents the idea of utility that drives any evaluation: the basic idea is that evaluation expresses what some object is worth to some kind of user: V expresses `worth'. As said above, utility may sometimes be related to money, but this cannot in general be assumed. We will tentatively define V as linearly ordered. This means that we can at least define relative utility by mapping object-user pairs to V.
O represents objects of evaluation. Anything can in principle be evaluated, including dish washing machines, project proposals, progress in ongoing work, and evaluation procedures. In the TEMAA project, we restrict O to computer programs containing some linguistic knowledge (and, more specifically, to spelling checkers and grammar/style checkers). The object of evaluation can be structured, i.e. it can sometimes be seen as a structure of components or functionalities that can serve as objects of evaluation themselves. For example, a text processor can contain a spelling checker and a grammar checker. An evaluation-related question about the package as a whole may for example examine its integratedness, or the requirements it imposes on the hardware platform. Other questions pertain to components: for example, the update/maintenance properties of a private dictionary for the spelling checker.
U represents `users', i.e. people or organisations that are (potentially) interested in members of O. The notion of `user' is philosophically complicated. It is itself a two-place predicate: users are users of objects. Perhaps the best view is to see a user as a certain desire. In the ISO proposal, such a desire is called `quality requirements'. Users come in kinds. For example, the owner of a translation bureau may have a different perspective from a translator she employs. The latter may find aspects of `user-friendliness' of some computer tool more important than the former.
All the factors which are often called environmental or situational variables help to define the user's desires, and are therefore seen here as part of the definition of U. If we are considering a system which can be broken down into distinguishable components, some of which may be subject to individual evaluation, we can even go so far as to say that the constraints one component of the system imposes on another (for example in the form of required output) form part of the user's desires: the user wants a task to be performed, and therefore wants all the sub-tasks of that task to be performed. Thus U includes not only all the constraints and desires consequent on the user's environment, but also, where relevant, the constraints imposed by sub-components of an overall system which might fulfill the user's needs.
We should also keep in mind that all relevant distinctions in the contexts of use can be seen as distinctions amongst types of users. In future work, U may be broken down to reflect the granularity of these distinctions. It should then become possible to see U itself as a function of conditions such as a particular kind of writer population, some specific bias in spelling errors, the fact that a PC has to be used as the hardware platform, etc.
The basic function given above can be curried in two ways, obtaining two perspectives on evaluation:
O (U V) describes the `object-based' picture: given some object, evaluation tells us who likes it
U (O V) gives the `user-based' picture: given some user, evaluation tells us what s/he likes
What the basic evaluation function tells us in practice is that each evaluation will need descriptions of objects and descriptions of users, in order to arrive at evaluation results.
In the current project, we have decided to make the implementation feasible by defining user types essentially as specifications of objects that are useful to them. For example, one can define some type of user of a spelling checker by stating that it should find at least 95% of the spelling mistakes, should run on a PC, and should have useful suggestions for mistakes found. In other words, we use descriptions of classes of objects to define user types. In theory, one should be more principled and analyse a user in terms of some more general human motivation, deriving the specifications of desired objects from that. However, this line of thinking is extremely difficult to make precise. Therefore, the ISO notion of `quality requirements definition' is phrased as constraints on objects. We will therefore consider first how objects are described; after that, we will clarify in more detail how we describe users.
Feature descriptions
A central role in practical evaluation is played by descriptions of objects (and components thereof) in ways that help to determine their utility value for various kinds of users. We think it is attractive to describe objects of evaluation in terms of typed feature structures, i.e. pairings of a type and an attribute-value structure.
An object type corresponds to a class of objects in O defined by the fact that some specific function is executed by all the objects in a class. Some possible object types in our domain are: editor, spelling checker, grammar checker. A program will usually be indicated by a concrete or agentive noun, e.g. `X checker'. The function it performs is usually indicated by a nomen actionis, e.g. `checking X'. We will use types indiscriminately to denote both the programs and the functions they fulfill.
An attribute refers to a property to which can be assigned, for some given member of O, one of a range of values. For example, some C compiler can be described by attributes like speed, version of the language, various debugging options, etc. Some car can be described by attributes like speed, fuel consumption, various attributes related to safety, etc.
We will associate with each object type T its unique set of attributes AT.
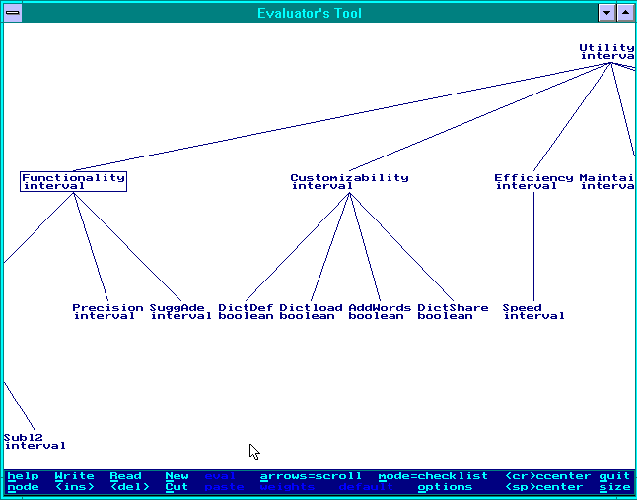
Examples of attributes for the type spelling checker are:
recall, i.e. the degree to which it accepts valid words (does not produce `false flaggings')
precision, i.e. the degree to which it rejects invalid words
suggestion adequacy, i.e. the degree to which it produces correct replacements
customisability, for example the possibility to create and maintain specific extra word lists
Attributes are typed according to their possible values. The range of values (scale) can for example be boolean (yes/no), nominal or classificatory (a set of unordered values), ordinal (an ordered range of values), or interval/ratio (ordered values with meaningful differences).
A set of attributes can be structured in the sense that the value of some attribute may be a new set of attribute-values. For example, the spelling checker attributes recall, precision, and suggestion adequacy may be grouped together under the attribute `functionality'. Therefore, an attribute-value description will typically be a tree.
The attributes should be chosen with a view to their relevance to utility. Some general principles guiding the selection of evaluative attributes are summarised in the section on ISO 9126 above.
On the other hand, the attributes should be chosen in such a way that it is possible to establish, for a given object, what values it takes. That is, each attribute in some AT is associated with a method to obtain its value for any member of the object type T. For attributes that are groupings of other attributes, the method will be some function on the values of the sub-attributes. For `terminal attributes', the method will be some measurement technique to be applied to members of T directly.
The matrices one typically sees in consumer-oriented evaluations of products are attribute-value descriptions in this sense.
Descriptions of objects of evaluation
Members of O perform functions, functions are characterised by types and attributes, attributes take values. Splitting up a software item in terms of a typed feature structure will be called featurisation in this report. Each type of feature can allow recursive refinement into subfeatures.
A feature is an attribute-value pair. For example, `recall = 90%'.
A feature checklist is like a featurisation, but the values are left open. For each object type, there will be a unique feature checklist. An example of a feature checklist for spelling checkers is given as part of TEMAA deliverable D17.
A test is an object that produces values for a given attribute, given members of T. Tests can be typed by attributes tested, inputs, outputs, tools, procedures, personnel, duration.
A quality characteristic is an attribute. In some usages, it is an attribute that is `high in the tree'. See for example the characteristics listed in the section on ISO 9126.
Descriptions of users
As said above, we describe users in terms of the objects they like. That is, we associate extra information to a feature checklist, by which we express a user type in terms of preferences and constraints on the attribute values.
For each terminal attribute, we specify the range of acceptable values and the optimal value. For each non-terminal attribute, we define the function from the values of its sub-attributes. This may involve differential weights, for example, some user type may find recall more important than precision in a spelling checker. See also the section on ISO 9126 above.
Also, users may differ in the attributes they would like to see the values of. Some users may only be interested in the final utility value (and look only at the `best buy'). Others may be interested in the values obtained on specific sub-attributes. A reportable attribute is an attribute that is of interest to a user type.
A specification is a constraint on featurisations. For example: `recall 90%'.
`Criterion' as the word is used in ordinary language can be defined as synonymous to specification (though the pragmatics of the two words are different). Some authors use it as a synonym of `attribute'.
A norm is, again, a constraint on featurisations. Norms can be used in a prescriptive way (which makes the word very similar in pragmatic meaning to specification) or in a descriptive way (describing the state of the art).
A user profile defines a class of users. Formally speaking, it is a feature checklist with the following additional information per attribute:
For each attribute: Indication of whether it is reportable or not reportable;
For terminal attributes: Minimum and maximum values that are acceptable, and the optimal value;
For non-terminal attributes: Function from values of daughters, possibly including weights of the daughters reflecting their relative importance for this kind of user.
If we understand the ISO 9126 report well, then the minimum/maximum/optimum values correspond to what this ISO report calls `rating level', and the reportability indication and the weights correspond to what the report calls `assessment criteria definition'.
An important achievement of the TEMAA project has been the design of a formal framework for evaluation, which is embodied by a device capable of carrying out evaluations on the basis of this formal framework.
This device must be fed with descriptions of objects to be evaluated, with descriptions of the user's requirements, and with the evaluation measures and methods to be applied. Its output is an evaluation report on the product or products evaluated.
Since, at each moment in time, new object descriptions, user requirements, measures and methods can be added, we will call this device a Parameterisable Test Bed (PTB).
The PTB is a computer program that
is fed with parameters describing objects of evaluation, and classes of users (in a broad sense) of these objects;
consults a library of test methods;
carries out the relevant tests; and
produces the evaluation report.
Objects of evaluation could be any NLP application, e.g. spelling checkers, style checkers, information retrieval systems, translation systems or aids.
Objects are (in accordance with our formal framework) described in terms of attributes and values. The set of objects is structured. Objects may be subtypes of other objects, and classes of objects may have components in common.
User requirements are formulated in terms of constraints on attributes and their values, and weightings of the relative importance of the attributes and their values.
The PTB has a library of descriptions of objects and users, attributes and ways of establishing their values, and results of earlier measurements. For some of the attributes it will be possible to design automated methods to obtain their values for each instance of the object (e.g. error correction precision and recall). Others will ask the operator to provide specific data (e.g. the price of the instance), and yet others may provide the operator with a recipe for obtaining the value (e.g. a questionnaire to be sent out to 100 users).
The actual testing will consist of collecting all values for the relevant attributes, either in an automated way or partly or entirely by hand. The result will be a full set of attribute-value pairs for one or more specific instances of an object. Note that this data collection is not dependent on any specific user type: the data are neutral with respect to user types.
The last phase is the assessment of the instances. Here the user requirements play a central role in that the relations between the various attributes and their weightings will determine which scores will be assigned to the products, and how they will be ranked.
In chapter 4, we describe some ingredients of a PTB that were developed in the course of the TEMAA project.
Summary of evaluation actions when using a PTB, and corresponding items mentioned in ISO 9126:
1. Define object types and feature checklists (not explicit in ISO 9126 but clearly related to what ISO calls users' requirements definition)
2. Collect objects of evaluation (e.g. actual spelling checkers) (not explicit in ISO 9126)
3. Define user profiles (ISO 9126: users' requirements definition, as well as preparation phase, definitions of rating levels and assessment criteria; it is not clear whether ISO uses an explicit concept of `user profile')
4. Define methods for assigning values to attributes for given objects of evaluation (ISO 9126: preparation phase, selection of metrics)
5. Create test materials (ISO 9126: probably sub-part of selection of metrics)
6. Perform tests, collecting basic data, turning feature checklists into featurisations (ISO 9126: do measurement)
7. Perform an evaluation (ISO 9126: rating and assessment)
8. Generate a report (not explicit in ISO 9126)
Contrary to ISO 9126, we do not assign these actions to well-defined `phases'. But it should be clear that such phases are implicitly defined; for example, one can write a report only after having performed an evaluation; performing an evaluation can be done only after one has defined user profiles and collected test results; performing tests depends on prior definition of tests, creation of test materials, and collection of evaluation objects. But the PTB approach is directed towards a certain modularity so that one can accommodate new evaluation objects, new object types, new user profiles, new test techniques at all times, thereby providing some re-usability.
It is based on a formal framework, which gives it a solid foundation
Its inherent flexibility makes it easily adaptable to new types of objects and requirements of new types of users
The fact that it is a library of independent modules ensures optimal re-usability across objects
It provides an environment in which automated and manual measuring methods can coexist in a natural way.
Action 1: A useful structuring device to guide the process of defining attributes and value types for object types and user profiles is a task model. A task model distinguishes language processing tasks, and document flows and stores associated with them. It will pinpoint the place in the document flow of the object type under consideration, and identify roles in the document flow upstream and downstream of that point which may affect requirements. For instance, relevant document processing upstream of a spelling checker may include Optical Character Recognition, as well the original writer of the document. The writer is clearly a complex role which, for a spelling checker, can be decomposed as a range of types of spelling error writers may be prone to. Downstream processing might include subsequent use by an automatic system which has a limited vocabulary, or separate requirements for US and UK English versions of a document. Interactive processing requirements on spelling checkers pertain to the semi-automatic nature of the task, and are related to the capacities and needs of the user co-editing the document with the aid of the spelling checker, e.g. for explanations and examples as well as just replacement suggestions. A generic task model for a given task type, such as spelling checking, includes a range of possible organisational, operational, usability and workflow factors that may used as a guide for the development of featurisations and user profiles for any particular evaluation. Development of a task model can be seen as a phase of requirements definition prior to formalisation in object and user descriptions of the sort presented below.
Action 2: Define object types and feature checklists. For example, one object type is spelling checkers. It has to be defined what attributes are relevant to their evaluation, and what kind of values these attributes take. Attributes typed for their possible values are called measures in this report. A collection of such attributes can be a hierarchy: an attribute such as functionality may have sub-attributes such as recall, precision. A typed attributes hierarchy is called a feature checklist. Per object type, there is a unique feature checklist. As of here, we will call attributes that are composed from subattributes nonterminal attributes while attributes which are `leaves' of a checklist will be called terminal attributes. Here is an example checklist (partially represented) for the object type of spelling checkers (attributes are typed only as `interval' or `boolean'), figure 1:
Figure 1.
Action 3: Collect actual objects of evaluation.
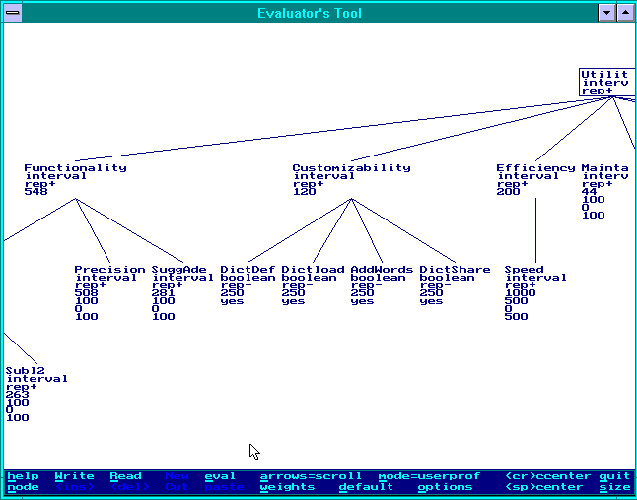
Action 4: Define user profiles. A user profile defines a user type. It is based on a feature checklist but adds some information that is specific to a given user type:
Which of the attributes are reportable attributes to this user type, i.e. for which attributes should the values be given explicitly in the evaluation report. In the example below, we see a user type who are not interested in a report on the specifics of customizability, but who want to see the general customizability value along with various other values.
The relative importance of an attribute relative to its `sister' attributes. In the example below, this is expressed as values between 0 and 1000, and sister attributes sum up to 1000. It can be seen that the example user cares much more about functionality than about the other main quality characteristics, that s/he cares more about precision than suggestion adequacy, etc.
For terminal attributes: the range of relevant values (this relates of course to the way in which
these attributes are tested -- see below), and the optimal value. In figure 2, three values are given for terminal attributes on interval scales: maximum, minimum, and optimum. For example, the Precision attribute is assumed to be expressed as a percentage, so the maximum and minimum are 100 and 0 and the optimum is 100 (perfect precision). In the same example, for Boolean attributes only the optimum is given as the range is always [yes,no]. Values outside the range will be considered as `useless'.
Figure 2.
Action 5: Define methods for assignment of values to attributes. For terminal attributes, this means definition of tests on actual objects of evaluation. In this project, we have attempted to define test procedures with an emphasis on repeatability (reliability) and efficiency, so that these tests can grow into real benchmarks. Wherever possible, this implies that one tries to automate the testing procedure. This is, however, not possible for all attributes. For example, there are no clear procedures for many attributes essentially involving human judgement (e.g. user-friendliness and related attributes). The ASCC program (described in chapter 4) is an example of automated testing
of spelling checkers w.r.t. the functionality attribute and its three sub-attributes. Methods for the assignment of values to nonterminal attributes are functions from the daughters' values. In this project, where a user profile assigns weights to sub-attributes, we (essentially) used weighted averages to compute values up the attributes tree, up to the root (always labeled `utility').
Action 6: Create test materials. For most tests, materials will be necessary, like in the case of spelling checkers, the tests use lists of correct words of a language as well as lists of incorrect words (to test precision and suggestion adequacy). Like all other aspects of testing, this should be standardized and automated. In this project, we use a program to construct incorrect words from correct words, thus simulating a person (or other writing device) making spelling errors. An error type can be defined by a set of `corruption rules', which are essentially regular expression-based substitute operations. See the description of the Errgen program in chapter 4. The idea is that in this way, one can not only test precision (the number of items in a list that are accepted by a spelling checker) but also suggestion adequacy (by comparing the suggestions to the correct word from which the incorrect word was derived).
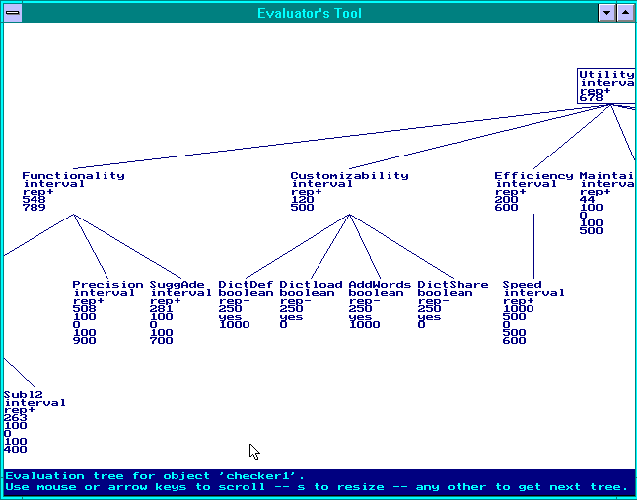
Action 7: Perform tests. I.e. obtain values for terminal attributes on the basis of the methods and materials defined in the previous components.
Figure 3.
Action 8: Perform an evaluation. Using results of component 6 and a given user profile, evaluate a set of objects, i.e. compute the value of the root attribute utility for each member of the set. This process can be repeated for several user profiles on the basis of the same test results. Here is an example result (for a hypothetical spelling checker) figure 3, where the bottom number on each node represents the attribute-value (normalized to the range [0,1000]):
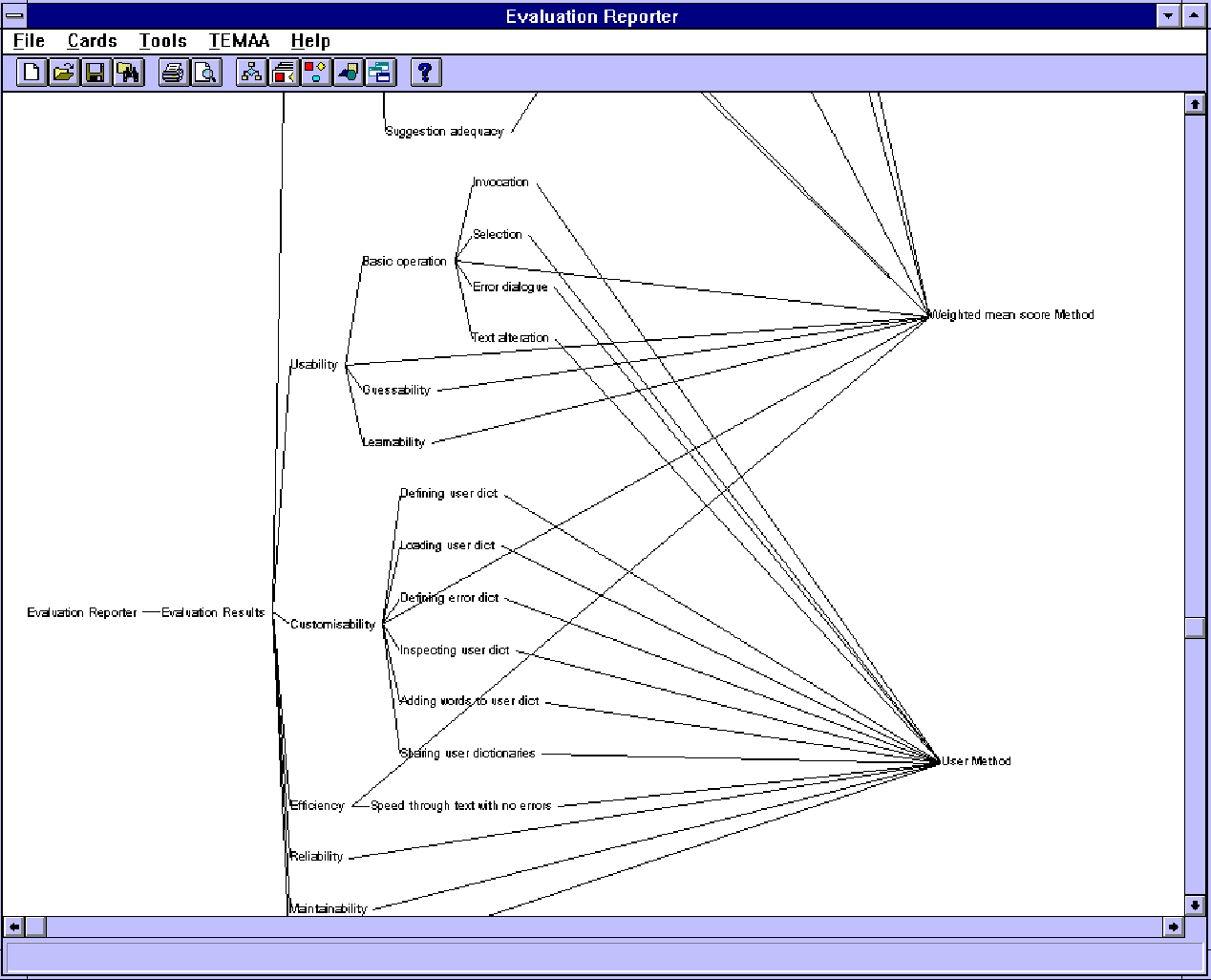
Action 9: Generate a report. In this project, we have developed a pleasant interface (called ER: evaluation reporter) for reporting. The users chooses a set of results from some previous running of Action 8; they are then displayed in an appropriate way, for example, as hypertext using the Hardy diagramming and hypertext tool (Smart, 1996), figure 4. A navigation window shows the hypertext structure of the whole document. The following screen dump shows the hypertext tree for all the quality characteristics, attributes and sub-attributes for spelling checker evaluation, figure 5.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
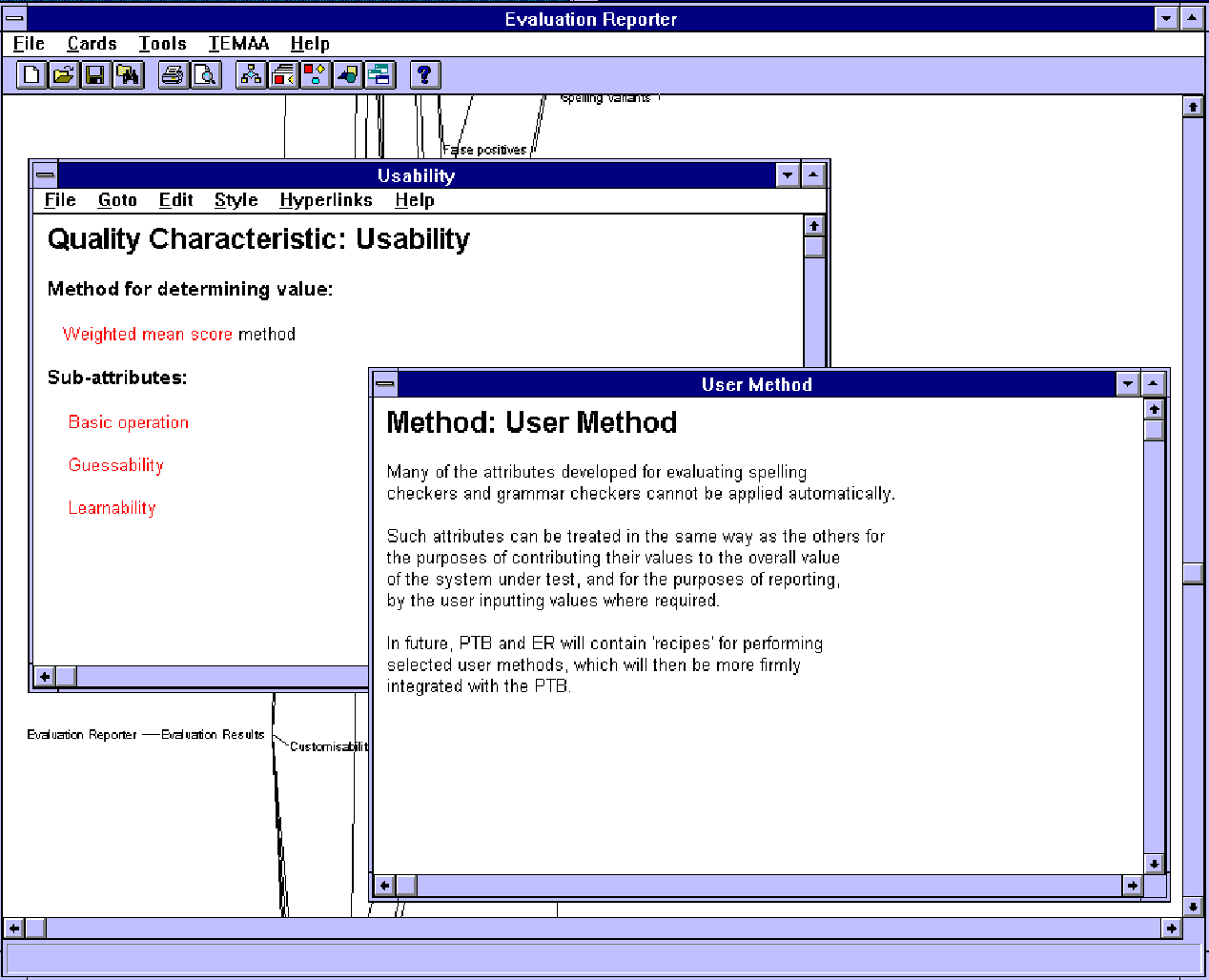{kind=link}